這些假臉實在太逼真了!英偉達造出新一代 GAN,生成壁紙級高清大圖毫無破綻

不敢相信,上面這些人臉,全都是假的。
是英偉達的 AI 生成的。
借用風格遷移的思路,團隊為 GAN 創造了一種新的生成器。
連 GAN 之父 Goodfellow 老師也忍不住發推稱讚優秀!

這個結構不需要人類監督,可以自動分離圖像中的各種屬性。這樣,在或粗糙或精細的不同尺度上,人類便能自如地控制 GAN 的生成。
另外,英偉達的人臉生成模型,支持 1024 x 1024 的高清大圖生成。畢竟,GAN 從小吃的是高清數據集。團隊還説,數據集很快就要開源了。
實際效果展示

人物自然,背景自然,邊緣又自然。足以騙過我這個普通人類的肉眼了。
輸入兩張圖,圖 A 決定生成人物的性別,年齡,頭髮長度,以及姿勢;一張決定其他一切因素:比如膚色、髮色、衣服顏色等等。
這樣,就可以把圖 B 的一部分人物特徵,遷移到圖 A 上了:

不過,人臉的朝向和表情,還是 A 的。
就算人種發生劇烈變化,也絲毫不會違和。你看,把非裔人類的臉部特徵 “移植” 給四位白種人,嘴脣的厚度、鼻子的形態,以及額頭,都有明顯的變化。

再來看看從不同尺度調節的效果吧。
這是粗糙尺度 (Coarse Styles) ,也是三種尺度中最大規模的調整,會涉及臉部朝向的變化,臉型和髮型也是在這裏調整的:

然後看看中間尺度 (Middle Styles) ,調整僅限於面部特徵和髮色髮量了,姿勢、髮型、臉型都不會有明顯變化:

再來就是精細尺度 (Fine Styles) ,只是調整圖像的配色,幾乎不會給人物變臉了:

全新的生成器
我們前面説過,這個 GAN 不用人類監督,就可以自動分割圖像裏的各種部分。
經過訓練,它就可以把這些部分,按照一定的方式組合到一起。
具體怎麼組合呢:
這種新的生成器,像風格遷移算法一樣,把一張圖像,看做許多風格 (Styles) 的集合。
每種風格都會在一個不同的尺度 (Scale) 上控制圖像的效果:
引用粗糙 (Coarse Styles) :姿勢、頭髮、臉型。
中度 (Middle Styles) :面部特徵、眼睛。
精細 (Fine Styles) :配色。
三者組合在一起,才是最終的生成結果。
調節不同 “風格”,就可以在不同尺度上調節人臉圖片。

另外,這隻 GAN 還可以自動把那些無關緊要的變化 (Inconsequential Variation) 剔除出去。
引用所謂無關緊要,就是説畫面發生了變化,但看上去主角還是原來的主角。
粗糙的噪音:如大尺度上的捲髮程度。
精細的噪音:更加精細的細節,如質地等。
無噪音:沒有特徵的、像畫畫一樣的樣子 (Featurelessly “painterly” look) 。

相同圖片,輸入不同的噪音,效果就不一樣。
人類也可以選擇,每種 Style 的強度 (Strength) 多大。
選擇高強度 (High Strength) 的話,生成的圖像就會比較多樣化,但生成壞圖也會有一些。
如果是低強度 (Low Strength) ,生成的圖像之間不會有太多變化,但也幾乎不會出現壞圖。
從結構上來看,這個新的生成器是這樣的:
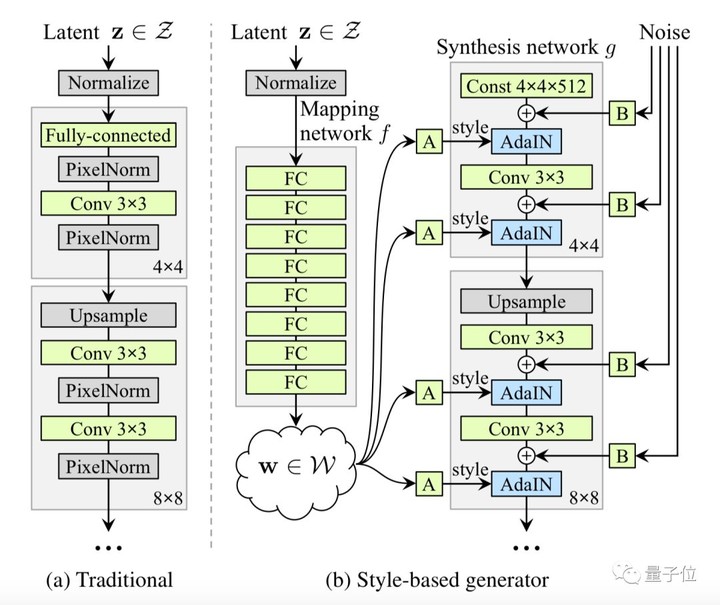
傳統的圖像生成器僅通過輸入層提供潛在編碼(Latent Code),英偉達從一開始就捨棄了這種設計方案。
就像上圖展示的那樣,他們設計的新生成器先將輸入從潛在空間 Z 映射到中間的潛在空間 W,將映射網絡生成結果輸入到下一層。在生成網絡 g 每次卷積運算之後,加入高斯噪聲(Gaussian noise),也就是圖像的隨機變化。
圖像在不同尺度上的 “風格”,就是由上面的每個卷積層控制的,它實現了直接控制各層級的圖像特徵強度(Strength)。
從生成圖像中的隨機自動變化中。它可以無監督地從中分離出圖像的 “風格”。
發佈更強人臉數據集
除了發佈圖像生成算法外,英偉達從 Flickr 中選取了 7 萬張 1024×1024 分辨率的照片,形成了一個新的人臉數據集 FFHQ(Flickr-Faces-HQ)。

它能提供了高度多樣化、高質量的人臉數據,並且涵蓋了比現有高分辨率數據集(如 CelebA-HQ)更多的變化,比如更多佩戴眼鏡、帽子的照片。
英偉達將在不久後公開提供此數據集,並放出源代碼和預訓練網絡。
最後,給廣大貓奴們送出福利。英偉達的圖片生成器不僅能用於人臉,研究人員還用 LSUN 數據集造出了很多貓咪的圖片。

你能看出它們都是假的嗎?
本文來自微信公眾號量子位(ID:QbitAI),作者為栗子、曉查,愛範兒經授權發佈,文章為作者觀點,不代表愛範兒立場。
資料來源:愛範兒(ifanr)