蘋果、Google、微軟、亞馬遜,哪家的語音助手會的語言最多?

2018 年 9 月,一家叫 Vocalize.ai 的人工智能初創公司做了一項測試,它比較了 Google、蘋果和亞馬遜的智能語音助手,發現了一些有意思的事情。
比如,三家語音助手都能很好地識別美式口音和印度式口音的英語,但 Siri 和 Alexa 在識別中式口音時,準確度都大幅下降。
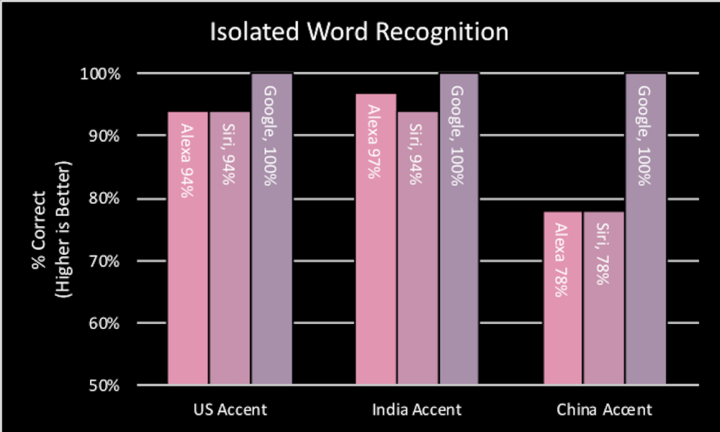
對語音助手來説,識別同一種語言的不同口音已經是個挑戰,而要「學會」一種新語言則更加困難。
比如,直到今年秋天,三星的 Bixby 才會增加對德語、法語、意大利語和西班牙語的支持,這些語音加起來有超過 6 億的使用者;微軟的 Cortana 用了很多年才支持西班牙語、法語和葡萄牙語。
在人工智能取得重大突破並飛速發展的今天,為什麼語音助手的發展如此緩慢?人類要重建巴別塔,該如何努力呢?
為什麼語音助手支持一種新語音這麼難?
語音助手要「學會」一門語言主要有兩個大課題:聲音識別和聲音合成。
聲音識別又分成兩個部分,第一步是將語音轉成文字的語音識別,第二步是語義理解,涉及的技術主要是自然語言處理。
深度學習的突破是人工智能在最近幾年飛躍發展的重要原因。目前,語音研究領域也主要使用深度神經網絡——一個像人類神經一樣的分層數學函數,可以不斷自我學習和進步。

▲ 圖片來自:electronicsweekly
這已經是一個巨大的進步。過去的自動語音處理技術(ASR)主要依賴手動調整的統計模型來計算短語中詞組合的概率,深度神經網絡不僅降低了錯誤率,而且在很大程度上避免了人為監督的需要。
但基礎的語言理解還遠遠不夠,本地化依然是個巨大的挑戰。有技術人員透露,目前,根據要涵蓋的意圖,新語言構建查詢理解模塊需要 30 到 90 天。如開頭所説,即使是識別同一種語言的口音,都是巨大的挑戰。
不同語言的差別更大。比如在語法層面,英語中形容詞通常出現在名詞前,而副詞既可以在前,也可以在後。對語音助手來説,這就很容易產生迷惑,比如「海星」(starfish)這個詞,語音轉文字的引擎很容易將「星星」(star)理解為「魚」(fish)的形容詞。
將語音處理為文字並加以理解後,語音助手還必須以人類的聲音來回復。
傳統的語音合成技術主要包括一個合成引擎和一個預先錄入的語音數據庫,合成引擎通過計算機軟件查找語音數據庫中匹配的讀音把文本轉化為語音。但是,這種「人造的語音」非常不連貫,聽上去也很不自然。為了覆蓋更多的詞,傳統的語音數據庫通常也非常大。
現在的語音合成技術被稱為 TTS(文本轉語音),它使用數學模型重新創建聲音,然後組合成單詞和句子。 最新的 TTS 同樣引入了深度學習,可以在「訓練」的過程中越來越強。
目前,相比語音識別和語義理解,語音合成的技術要成熟很多。中國各大互聯網公司也經常在運營活動中使用語音合成技術。
幾大語音助手分別支持哪些語言
Google Assistant
Google 的語音助手支持的語言最多,目前它在 80 個國家支持 30 種語言,包括:
- 阿拉伯語(埃及,沙特阿拉伯)
- 孟加拉語
- 中文(繁體)
- 丹麥語
- 荷蘭語
- 英語(澳大利亞,加拿大,印度,印度尼西亞,愛爾蘭,菲律賓,新加坡,泰國,英國,美國)
- 法語(加拿大,法國)
- 德語(奧地利,德國)
- 古吉拉特語
- 印地語
- 印尼語
- 卡納達語
- 意大利語
- 日語
- 韓語
- 馬來語
- 馬拉地語
- 挪威語
- 波蘭語
- 葡萄牙語(巴西)
- 俄語
- 西班牙語(阿根廷,智利,哥倫比亞,祕魯)
- 瑞典語
- 泰米爾語
- 泰盧固語
- 泰語
- 土耳其語
- 烏爾都語
蘋果的 Siri
2018 年被 Google Assistant 超過後,Siri 目前支持的語言數排第二名。包括 36 個國家的 21 種語言:
- 阿拉伯語
- 中文(普通話,上海話和廣東話)
- 丹麥語
- 荷蘭語
- 英語
- 芬蘭語
- 法語
- 德語
- 希伯來語
- 意大利語
- 日語
- 韓語
- 馬來語
- 挪威語
- 葡萄牙語
- 俄語
- 西班牙語
- 瑞典語
- 泰語
微軟的 Cornata
- 簡體中文
- 英語(澳大利亞,加拿大,新西蘭,印度,英國,美國)
- 法語(加拿大,法國)
- 德語
- 意大利語
- 日語
- 葡萄牙語(巴西)
- 西班牙語(墨西哥,西班牙
亞馬遜的 Alexa
- 英語(澳大利亞,加拿大,印度,英國和美國)
- 法語(加拿大,法國)
- 德語
- 日語(日本)
- 西班牙語(墨西哥,西班牙)
三星的 Bixby
- 英語
- 中文
- 德語
- 法語
- 意大利語
- 韓語
- 西班牙語
未來會如何發展?
在語音識別、語義理解和語音合成領域,它們取得進步的主要原因是引入深度學習。
未來,更加依賴機器學習可能對語音領域的研究有更大的幫助。
「處理多語言支持伴隨着不同的語法規則,這也是目前主要的挑戰之一,語音處理模型必須考慮並適應這些語法規則,」人工智能公司 Clinc 的副總裁 Himi Khan 解釋到,「大多數自然語言處理模型採集句子,進行詞性標註——在某種意義上識別語法,並創建規則來確定如何解釋該語法。」
▲ 傳説中的巴別塔,因上帝將人類的語言打亂而中止建設. 圖片來自:jonathanpark

而未來,如果有了一個真正的神經網絡堆棧——一個不過多依賴語言庫、關鍵詞和詞典的系統,可以將關注語言改為研究詞的嵌入,以及嵌入後的連接模型。那麼,「它就可以應用在幾乎所有語言的語音識別上。」
這只是一個研究方向。但總體來説,使用海量的真實對話作為語料供機器學習,而不過多依賴人工定義的識別模型,可以有效地幫助語音助手更加「聰明」。
題圖來自:thewiredshopper
資料來源:愛範兒(ifanr)