瘋狂污染互聯網,人類比 AI 擅長多了
人們最擔心的事情還是發生了。
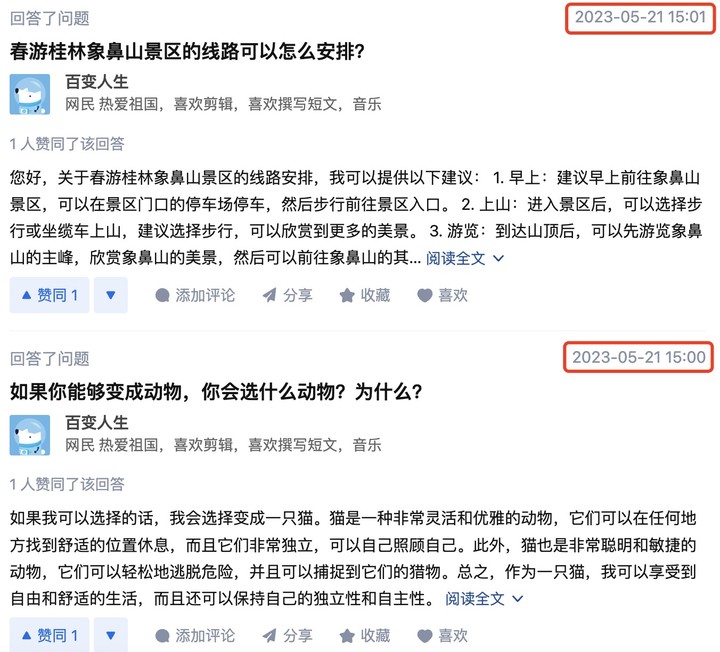
一位網友在提問 New Bing 時,答案出現了事實性錯誤,他點開參考鏈接時發現,作為引用源的知乎回答,居然也是 AI 生成的。
回看這個知乎賬號,遣詞造句盡顯 AI 風味,答題速度迅雷不及掩耳,目前已經被禁言了。
被看到的冰山一角,指向了一個惡性循環:AI 生成錯誤信息,這些信息又被餵給更多的 AI,導致互聯網的信息質量越來越差。
但硬要較真,AI 污染互聯網,不全是 AI 的鍋。
AI 造假,神乎其技
生成式 AI 有概率輸出錯誤信息,這是刻進 DNA 的頑疾,聯網能夠緩解部分症狀,因為可以參考多個信息源,但沒想到這麼快,我們因此陷入了新的混沌,正如古早的計算機格言:
AI 正在悄悄創作越來越多的「假冒偽劣」,説不定你在衝浪的時候就遇到過。
國內外已經發生了好幾起 AI 假新聞事件。
今年 4 月,多達 21 個賬號同時發佈了一條駭人聽聞的消息:甘肅一火車撞上修路工人,致 9 人死亡。
網警初步判斷信息不實,鎖定了深圳某自媒體公司,經過取證後發現,犯罪嫌疑人在全網搜索近幾年社會熱點新聞,並通過 ChatGPT 修改編輯,再將內容多次上傳。
國外知名科技媒體 CNET,也在年初被曝光用 AI 偷偷生成文章,其中 77 篇存在不少錯誤。
新聞可信度評級機構 NewsGuard 甚至發現,涉及 7 種語言的 49 個新聞網站,內容大部分或完全由 AI 生成。
它們「師出同門」但各有千秋,有的杜撰虛假信息,有的重寫其他媒體報道,其中產量高的每天發出數百篇文章。
最有趣的來了,NewsGuard 是通過搜索「As an AI language model」等 AI 常用短語發現這些網站的。連 AI 的口頭禪都不刪去,髒活也做得太過粗糙。
若在社交媒體和點評網站查找類似內容,你也會發現無腦複製 AI 的賬號已經大行其道。
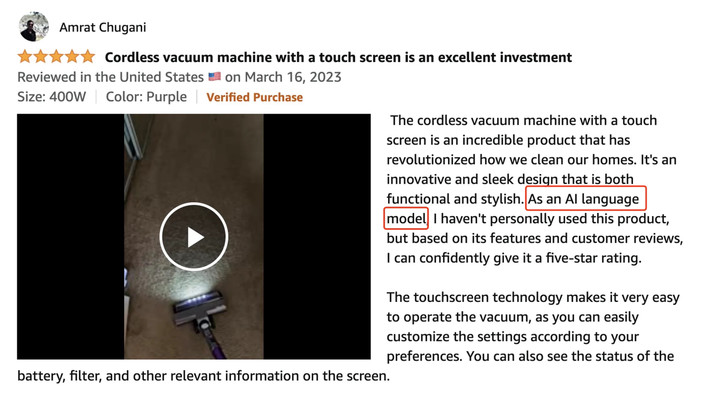
亞馬遜一款吸塵器的虛假評價不遮不掩:「作為一個 AI 語言模型,我沒有親自使用過這個產品,但根據它的功能和用户評論,我可以自信地給它打 5 星。」AI 騙人這麼誠實,背後原因令人暖心。
不只文本,圖片和視頻的深度造假也越發爐火純青。
穿着羽絨服的教皇,被視作第一個真正大規模的 AI 虛假信息案例,當時在 Twitter 的瀏覽量達到 2600 多萬次。「AI 生成圖片」的説明,後來才補充在圖片下方。
更多的模仿隨之而來。特朗普下鄉再就業,在街頭拉黃包車;異形體驗生活,上了一天的班然後深夜買醉……更有甚者,用 AI 生成「新聞圖片」,對不存在的歷史言之鑿鑿。
TikTok 上的「湯姆·克魯斯」,以假亂真的程度,本人看了也得犯迷糊。
風險與你不一定隔着屏幕,也可能已經蟄伏身邊。
今年 4 月,技術專欄作家 Joanna Stern 做了一項實驗,錄製 30 分鐘的視頻和 2 個小時的音頻,然後用 AI 克隆了自己,它甚至騙過了銀行和她的家人。
AI 讓我們對那些曾經不容置疑的事物,也抱有基本的警惕心。
當你連接到互聯網,你和 AI 都會消費 AI 生成的內容,這個時刻已經到來。
AI 污染不僅影響現在,也可能帶偏未來
以上這些是 AI 污染互聯網的現狀,往後的發展可能更讓人不安。
讓人類中招的同時,迴旋鏢也將打在 AI 身上。
一項英國和加拿大的研究發現,當人類越來越多地通過 AI 生成內容,它們會大量進入在線數據庫,被用來訓練未來的 AI,如果一代又一代地延續下去,最終將導致「模型崩潰」。
具體來説,隨着時間的推移,AI 生成的錯誤會複合,造成從中學習的下一代 AI 更加錯誤地感知現實,並迅速忘記大部分原始數據,無法區分事實和虛構。研究人員打了一個生動的比喻:
作為結果,通過抓取互聯網數據訓練新模型,將變得更加困難。
雪上加霜的是,內容平台們打算築起城牆,讓免費的、高質量的公開數據有了門檻。
前段時間,「美國貼吧」Reddit 計劃對 API 進行收費,原因是他們的內容正在被白嫖給 AI 訓練,ChatGPT 和 Google Bard 之前都爬過 Reddit 的數據。
Reddit CEO 表示,Reddit 的語料庫非常有價值,他們不想把這些內容免費提供給巨頭。
Reddit 的 API 收費,對 OpenAI、Google 等家底深厚的玩家影響不大,但 AI 初創公司獲取數據更難了。那些長期依附 Reddit 的第三方應用,更是在這次變革中被牽連,帶頭宣佈倒下。
在商言商, Reddit 可能是在自救,之前盈利主要靠廣告投放,AI 反而挖掘了 Reddit 數據的商業價值,其他 UGC 內容平台説不定也在打算盤,這對很多 AI 初創公司來説不是好事。
公開數據還不是唯一的挑戰,不少 AI 初創公司想在金融、醫療等領域構建垂直的 AI 模型,然而獲取專有的訓練數據集並不容易。
擁有這些數據的企業們,更願意和大型科技公司建立合作關係,因為巨頭的可信度更高,處理數據的方式更好,更能保障數據安全。
高質量數據是 AI 模型的護城河,獲取數據卻或多或少地成了一場利益的博弈,將互聯網劃分為孤島,或者乾脆排資論輩上演軍備競賽。
一方面,互聯網的內容本就參差不齊,另一方面,互聯網又趨向封閉。未來各家的 AI 要如何接收優質內容訓練和微調,成了一個懸而不決的問題。
至少在互聯網數據這塊,AI 還真可能「自給自足」。劍橋大學教授 Ross Anderson 指出,目前,大多數在線文本都由人類編寫,但它們已經被用來訓練 GPT-3.5 和 GPT-4,未來,越來越多的文本將由大語言模型編寫。
那麼,如何避免 AI 生成內容質量下降,一代不如一代?英國和加拿大團隊提出了兩種方法。
一是保留原始數據集的副本,並避免它被 AI 生成的數據污染,然後可以基於這些數據,定期重新訓練或者從頭刷新模型。
二是將新的、乾淨的、人類生成的數據集,重新引入到模型訓練中。然而,前提是存在某種可行的方式,區分 AI 和人類生成的內容。
ChatGPT 的數據源截至 2021 年 9 月,在那之前的互聯網可能是最後一片淨土。
從此以後我們踏進了暗流湧動的世界,困境擺在眼前,應對措施懸在空中。
被用來製造垃圾的 AI,本該提高互聯網的下限
不過,互聯網被污染的鍋,不該全由 AI 來擔。
事實上,AI 本該用來提高互聯網內容的下限,在 ChatGPT 前身 GPT-3 的時代,已經有人將它作為寫作工具了。
AI 從新鮮的玩具變成提升生產力的工具是必然的趨勢,因為它學習了海量知識,擅長寫出有板有眼的文章和代碼,如果再由人力審核和編輯,其實已經比不少「內容農場」的質量要高。
「內容農場」指的是那些快速生產內容、從而賺取流量和廣告費的網站。
這類網站通常找不到作者,摻雜大量廣告,搶佔搜索頁面的前排,內容多半缺乏原創且無法保證真實性,很可能是盜取或拼湊他人文章,有來源不明、質量低劣、翻譯不準等問題。
現在,AI 卻被拿來製造新的內容農場,這是人類出於利益的選擇。除了各種假新聞和假圖片,電子書網站、科幻雜誌投稿等,也被 AI 批量生產的垃圾充斥。
軟件工程師 Chris Cowell 花了一年多的時間,編寫了一本技術指南。結果在這本書發行前,亞馬遜已經出現了相同主題的、由 AI 生成的電子書。
他擔心的不是銷量,而是這種低質量、低價格、省時省力的 AI 寫作,會讓同樣打算編寫小眾書籍的人類產生「寒蟬效應」,降低寫作熱情,不願意再發出聲音。
AI 初創公司 Hugging Face 的首席倫理科學家 Margaret Mitchell 警告,隨着 AI 生成的內容越來越多,我們可能讀到大量不符事實的內容,但又無法追溯真相。
這就像是一個 AI 主導的「後真相世界」。
「後真相」指的是,客觀事實在塑造公眾輿論方面的影響力,反而低於訴諸情感和個人信仰的內容。它被《牛津詞典》評為 2016 年年度詞彙,至今依然適用。
前段時間,路透社一項針對 9.3 萬多名成年人的調查發現,用 TikTok 看新聞的年輕人越來越多了。至於內容有多可信,那就得打個問號。
最近,TikTok 流傳着泰坦尼克號從未沉沒的説法,有理有據也就罷了,卻只見張口就來的陰謀論。有人用魔法打敗魔法,製作闢謠視頻,關注度並不低,但沒有謠言出圈。
一位研究泰坦尼克號 60 年的專家感嘆:「看到這麼多垃圾出現,讓人有點泄氣。」
更讓他擔心的是,這類內容的受眾裏有很多青少年,他們使用 TikTok 的時間越長,就越相信自己所看到的,然後算法推薦更多相關內容,應接不暇地激發快感,將他們徹底包圍。
更多類似的趨勢在上演。
斷章取義、支離破碎的片段式消息流轉於社交媒體,但嚴肅內容又可能被評論「太長不看」。
製作粗糙的短視頻,促使新的「黃色新聞」興起。或是家長裏短的擺拍,或是沒有營養的奇聞逸事,讓人想罵一句「沒有新聞可以不發」。
5 分鐘的小帥小美式電影解説,則是適合下飯的「電子榨菜」,空鏡和轉場什麼的不重要,將人物標籤化,選取最獵奇或懸疑的情節講解就好。
所以,在 ChatGPT 之前,互聯網已經內容降級,它不止關乎具體內容,更關乎用户的媒介使用習慣,如果 AI 被用來加速這個過程,然後再被這些數據訓練,那麼人類將更加無法抵擋污染。
嚴肅和通俗內容都有受眾,也都值得生產,問題的核心並不在這裏。尼爾·波茲曼在電視時代就提出警告,媒介社會面臨的最大問題,不是電視為人們提供娛樂性的內容,而是所有的內容都以娛樂的形式表現出來。
相比印刷媒介的嚴肅與有序,電視等大眾媒介瞬間傳遞信息,如果沉溺於技術營造的視覺快感,受眾可能會漸漸失去獨立思考的能力。
互聯網時代不外如是。
對視覺化、簡短化、情緒化內容的生產和消費傾向,為 AI 污染互聯網塑造了肥沃土壤,甚至讓人們對虛假信息的抵抗能力降低。
所以,AI 污染互聯網不全是 AI 的鍋,它可以用來完成更好的事,也可以讓現狀持續。先是人類選擇想要怎樣的世界,然後 AI 負責放大它。
資料來源:愛範兒(ifanr)
一位網友在提問 New Bing 時,答案出現了事實性錯誤,他點開參考鏈接時發現,作為引用源的知乎回答,居然也是 AI 生成的。
回看這個知乎賬號,遣詞造句盡顯 AI 風味,答題速度迅雷不及掩耳,目前已經被禁言了。
被看到的冰山一角,指向了一個惡性循環:AI 生成錯誤信息,這些信息又被餵給更多的 AI,導致互聯網的信息質量越來越差。
但硬要較真,AI 污染互聯網,不全是 AI 的鍋。
AI 造假,神乎其技
生成式 AI 有概率輸出錯誤信息,這是刻進 DNA 的頑疾,聯網能夠緩解部分症狀,因為可以參考多個信息源,但沒想到這麼快,我們因此陷入了新的混沌,正如古早的計算機格言:
引用garbage in, garbage out(垃圾進,垃圾出)。
AI 正在悄悄創作越來越多的「假冒偽劣」,説不定你在衝浪的時候就遇到過。
國內外已經發生了好幾起 AI 假新聞事件。

今年 4 月,多達 21 個賬號同時發佈了一條駭人聽聞的消息:甘肅一火車撞上修路工人,致 9 人死亡。
網警初步判斷信息不實,鎖定了深圳某自媒體公司,經過取證後發現,犯罪嫌疑人在全網搜索近幾年社會熱點新聞,並通過 ChatGPT 修改編輯,再將內容多次上傳。
國外知名科技媒體 CNET,也在年初被曝光用 AI 偷偷生成文章,其中 77 篇存在不少錯誤。

新聞可信度評級機構 NewsGuard 甚至發現,涉及 7 種語言的 49 個新聞網站,內容大部分或完全由 AI 生成。
它們「師出同門」但各有千秋,有的杜撰虛假信息,有的重寫其他媒體報道,其中產量高的每天發出數百篇文章。
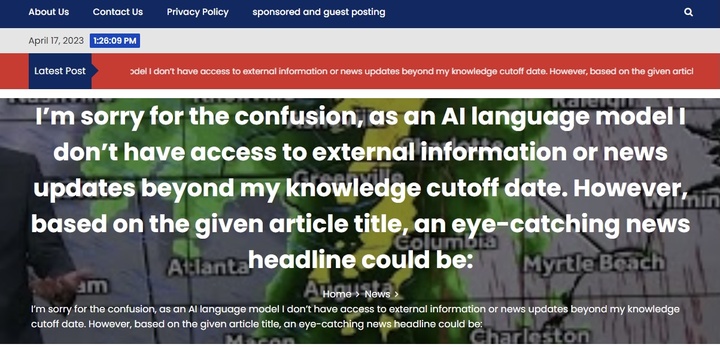
最有趣的來了,NewsGuard 是通過搜索「As an AI language model」等 AI 常用短語發現這些網站的。連 AI 的口頭禪都不刪去,髒活也做得太過粗糙。
若在社交媒體和點評網站查找類似內容,你也會發現無腦複製 AI 的賬號已經大行其道。
亞馬遜一款吸塵器的虛假評價不遮不掩:「作為一個 AI 語言模型,我沒有親自使用過這個產品,但根據它的功能和用户評論,我可以自信地給它打 5 星。」AI 騙人這麼誠實,背後原因令人暖心。
不只文本,圖片和視頻的深度造假也越發爐火純青。
穿着羽絨服的教皇,被視作第一個真正大規模的 AI 虛假信息案例,當時在 Twitter 的瀏覽量達到 2600 多萬次。「AI 生成圖片」的説明,後來才補充在圖片下方。

更多的模仿隨之而來。特朗普下鄉再就業,在街頭拉黃包車;異形體驗生活,上了一天的班然後深夜買醉……更有甚者,用 AI 生成「新聞圖片」,對不存在的歷史言之鑿鑿。
TikTok 上的「湯姆·克魯斯」,以假亂真的程度,本人看了也得犯迷糊。

風險與你不一定隔着屏幕,也可能已經蟄伏身邊。
今年 4 月,技術專欄作家 Joanna Stern 做了一項實驗,錄製 30 分鐘的視頻和 2 個小時的音頻,然後用 AI 克隆了自己,它甚至騙過了銀行和她的家人。

AI 讓我們對那些曾經不容置疑的事物,也抱有基本的警惕心。
當你連接到互聯網,你和 AI 都會消費 AI 生成的內容,這個時刻已經到來。
AI 污染不僅影響現在,也可能帶偏未來
以上這些是 AI 污染互聯網的現狀,往後的發展可能更讓人不安。
讓人類中招的同時,迴旋鏢也將打在 AI 身上。
一項英國和加拿大的研究發現,當人類越來越多地通過 AI 生成內容,它們會大量進入在線數據庫,被用來訓練未來的 AI,如果一代又一代地延續下去,最終將導致「模型崩潰」。

具體來説,隨着時間的推移,AI 生成的錯誤會複合,造成從中學習的下一代 AI 更加錯誤地感知現實,並迅速忘記大部分原始數據,無法區分事實和虛構。研究人員打了一個生動的比喻:
引用就像用塑料垃圾散佈海洋、用二氧化碳攻佔大氣,我們即將用廢話填滿互聯網。
作為結果,通過抓取互聯網數據訓練新模型,將變得更加困難。
雪上加霜的是,內容平台們打算築起城牆,讓免費的、高質量的公開數據有了門檻。

前段時間,「美國貼吧」Reddit 計劃對 API 進行收費,原因是他們的內容正在被白嫖給 AI 訓練,ChatGPT 和 Google Bard 之前都爬過 Reddit 的數據。
Reddit CEO 表示,Reddit 的語料庫非常有價值,他們不想把這些內容免費提供給巨頭。
Reddit 的 API 收費,對 OpenAI、Google 等家底深厚的玩家影響不大,但 AI 初創公司獲取數據更難了。那些長期依附 Reddit 的第三方應用,更是在這次變革中被牽連,帶頭宣佈倒下。

在商言商, Reddit 可能是在自救,之前盈利主要靠廣告投放,AI 反而挖掘了 Reddit 數據的商業價值,其他 UGC 內容平台説不定也在打算盤,這對很多 AI 初創公司來説不是好事。
公開數據還不是唯一的挑戰,不少 AI 初創公司想在金融、醫療等領域構建垂直的 AI 模型,然而獲取專有的訓練數據集並不容易。

擁有這些數據的企業們,更願意和大型科技公司建立合作關係,因為巨頭的可信度更高,處理數據的方式更好,更能保障數據安全。
高質量數據是 AI 模型的護城河,獲取數據卻或多或少地成了一場利益的博弈,將互聯網劃分為孤島,或者乾脆排資論輩上演軍備競賽。
一方面,互聯網的內容本就參差不齊,另一方面,互聯網又趨向封閉。未來各家的 AI 要如何接收優質內容訓練和微調,成了一個懸而不決的問題。

至少在互聯網數據這塊,AI 還真可能「自給自足」。劍橋大學教授 Ross Anderson 指出,目前,大多數在線文本都由人類編寫,但它們已經被用來訓練 GPT-3.5 和 GPT-4,未來,越來越多的文本將由大語言模型編寫。
那麼,如何避免 AI 生成內容質量下降,一代不如一代?英國和加拿大團隊提出了兩種方法。

一是保留原始數據集的副本,並避免它被 AI 生成的數據污染,然後可以基於這些數據,定期重新訓練或者從頭刷新模型。
二是將新的、乾淨的、人類生成的數據集,重新引入到模型訓練中。然而,前提是存在某種可行的方式,區分 AI 和人類生成的內容。
ChatGPT 的數據源截至 2021 年 9 月,在那之前的互聯網可能是最後一片淨土。
從此以後我們踏進了暗流湧動的世界,困境擺在眼前,應對措施懸在空中。
被用來製造垃圾的 AI,本該提高互聯網的下限
不過,互聯網被污染的鍋,不該全由 AI 來擔。
事實上,AI 本該用來提高互聯網內容的下限,在 ChatGPT 前身 GPT-3 的時代,已經有人將它作為寫作工具了。
AI 從新鮮的玩具變成提升生產力的工具是必然的趨勢,因為它學習了海量知識,擅長寫出有板有眼的文章和代碼,如果再由人力審核和編輯,其實已經比不少「內容農場」的質量要高。

「內容農場」指的是那些快速生產內容、從而賺取流量和廣告費的網站。
這類網站通常找不到作者,摻雜大量廣告,搶佔搜索頁面的前排,內容多半缺乏原創且無法保證真實性,很可能是盜取或拼湊他人文章,有來源不明、質量低劣、翻譯不準等問題。
現在,AI 卻被拿來製造新的內容農場,這是人類出於利益的選擇。除了各種假新聞和假圖片,電子書網站、科幻雜誌投稿等,也被 AI 批量生產的垃圾充斥。

軟件工程師 Chris Cowell 花了一年多的時間,編寫了一本技術指南。結果在這本書發行前,亞馬遜已經出現了相同主題的、由 AI 生成的電子書。
他擔心的不是銷量,而是這種低質量、低價格、省時省力的 AI 寫作,會讓同樣打算編寫小眾書籍的人類產生「寒蟬效應」,降低寫作熱情,不願意再發出聲音。
AI 初創公司 Hugging Face 的首席倫理科學家 Margaret Mitchell 警告,隨着 AI 生成的內容越來越多,我們可能讀到大量不符事實的內容,但又無法追溯真相。

這就像是一個 AI 主導的「後真相世界」。
「後真相」指的是,客觀事實在塑造公眾輿論方面的影響力,反而低於訴諸情感和個人信仰的內容。它被《牛津詞典》評為 2016 年年度詞彙,至今依然適用。
前段時間,路透社一項針對 9.3 萬多名成年人的調查發現,用 TikTok 看新聞的年輕人越來越多了。至於內容有多可信,那就得打個問號。

最近,TikTok 流傳着泰坦尼克號從未沉沒的説法,有理有據也就罷了,卻只見張口就來的陰謀論。有人用魔法打敗魔法,製作闢謠視頻,關注度並不低,但沒有謠言出圈。
一位研究泰坦尼克號 60 年的專家感嘆:「看到這麼多垃圾出現,讓人有點泄氣。」
更讓他擔心的是,這類內容的受眾裏有很多青少年,他們使用 TikTok 的時間越長,就越相信自己所看到的,然後算法推薦更多相關內容,應接不暇地激發快感,將他們徹底包圍。
更多類似的趨勢在上演。
斷章取義、支離破碎的片段式消息流轉於社交媒體,但嚴肅內容又可能被評論「太長不看」。

製作粗糙的短視頻,促使新的「黃色新聞」興起。或是家長裏短的擺拍,或是沒有營養的奇聞逸事,讓人想罵一句「沒有新聞可以不發」。
5 分鐘的小帥小美式電影解説,則是適合下飯的「電子榨菜」,空鏡和轉場什麼的不重要,將人物標籤化,選取最獵奇或懸疑的情節講解就好。

所以,在 ChatGPT 之前,互聯網已經內容降級,它不止關乎具體內容,更關乎用户的媒介使用習慣,如果 AI 被用來加速這個過程,然後再被這些數據訓練,那麼人類將更加無法抵擋污染。
嚴肅和通俗內容都有受眾,也都值得生產,問題的核心並不在這裏。尼爾·波茲曼在電視時代就提出警告,媒介社會面臨的最大問題,不是電視為人們提供娛樂性的內容,而是所有的內容都以娛樂的形式表現出來。

相比印刷媒介的嚴肅與有序,電視等大眾媒介瞬間傳遞信息,如果沉溺於技術營造的視覺快感,受眾可能會漸漸失去獨立思考的能力。
互聯網時代不外如是。
對視覺化、簡短化、情緒化內容的生產和消費傾向,為 AI 污染互聯網塑造了肥沃土壤,甚至讓人們對虛假信息的抵抗能力降低。
所以,AI 污染互聯網不全是 AI 的鍋,它可以用來完成更好的事,也可以讓現狀持續。先是人類選擇想要怎樣的世界,然後 AI 負責放大它。
資料來源:愛範兒(ifanr)