造「核彈顯卡」,已經不能滿足英偉達了
每年 8 月,英偉達都會在全球最重要的計算機圖形會議 SIGGRAPH 上秀一秀「肌肉」。
五年前,英偉達 CEO 黃仁勳在 2018 SIGGRAPH 發佈了首款支持光線追蹤的顯卡 Quadro RTX,這是英偉達自 G80 以來最重要的產品,把英偉達 GPU 從 GTX 時代推向了 RTX 時代。
彼時,英偉達還是一個非常純粹的圖形計算芯片廠商,滿腦子想的都是怎樣把 3D 渲染推向極致,其市值約為 814 億美元,還沒進入千億俱樂部。
但到了 2023 年,英偉達經歷了脱胎換骨般的鉅變。3 月份的 GTC 大會上,老黃拋出了金句「AI 的 iPhone 時刻已經到了」之後,英偉達的股價便開始節節攀升,不斷刷新歷史新高。
這五年之間,英偉達的股價漲了近 10 倍,當前市值已突破 11000 億,成為全球第一家市值突破萬億美元的芯片公司,也是當前市值僅次於蘋果、微軟、Alphabet、亞馬遜的美股第五大科技股。
英偉達的顯卡在市場上依然搶手,只是現在爭相搶購 GPU 的不再是那羣追求極致畫面的遊戲玩家,而是微軟、Meta 等急着部署和訓練大模型的科技巨頭。
在昨晚的 2023 SIGGRAPH 上,你已經再難聽到老黃説出遊戲、實時渲染、3D 等耳熟能詳的關鍵詞,取而代之的是生成式 AI、數據中心、加速計算等概念。
這是全新的英偉達,也是一個全新的時代。
英偉達變了
我們可以從英偉達的財報解讀這是一家怎麼樣的公司。
很長一段時間裏,遊戲業務一直是英偉達主營業務,直到 2023 年第一財季,在 PC 市場消費低迷和 AI 計算升温的雙重影響下,英偉達的數據中心業務終於迎頭趕上,成為了英偉達第一收入來源,這也標誌着英偉達正式從傳統的 GPU 供應商轉型成了全球最大的算力供應商之一。
在這之後,英偉達的數據中心開始一路狂飆,其 H100、A100 等計算顯卡成了 AI 行業的硬通貨,一度出現嚴重短缺。有分析師推測,全世界可能需要 43.2 萬張 H100 才能滿足市場需求。
英偉達最新一季的財報顯示,得益於企業們的強烈需求,英偉達的數據中心業務在 Q1 的營收約為 42 億,同比增長了 14%,環比增長了 18%,超出華爾街的預期。
但如果你覺得英偉達只是碰巧被 AI 熱錢砸中的幸運兒,那也太小看老黃了。
對英偉達來説,造「核彈 GPU」、投入 AI,這些不過是實現他們最終願景的所要做的「準備工作」,英偉達真正想要做的,是建設一個真正的元宇宙。
最先進的「鋤頭」
工欲善其事,必先利其器,英偉達深諳此理。
今年 3 月,英偉達發佈了 H100 NVL GPU、L4 Tensor Core GPU、L40 GPU 以和 NVIDIA Grace Hopper 四款 AI 推理芯片,以滿足企業們日益增長的算力需求。
5 月的台北電腦展上,老黃髮布了用 256 個 NVIDIA GH200 Grace Hopper 超級芯片組成的超級計算機 DGX GH200。
而就在昨天,老黃又發佈了搭載 HBM3e 內存新版 GH200,甚至連上一代的 GH200 還沒正式出貨,更新速度快得嚇人。
新舊 GH200 之間的差異主要集中在內存上。
GH200 Grace Hopper 是世界上首個搭載 HBM3e 內存的 GPU 芯片,內存容量從每個 GPU 96 GB 擴展到 144 GB,增加了 50% 。
HBM3e 內存是一種新型的高帶寬內存技術,在運算速度上 HBM3e 能比 HBM3 運算速度快 50%,提供最高 5TB/秒的傳輸速率。 這讓新版本的 GH200 運行 AI 模型的速度比當前模型快 3.5 倍。
其中,雙配置的 GH200 內存能達到 282 GB 的 HBM3e 內存,相比上一代的容量增加了 3.5 倍,帶寬增加了 3 倍。相比搶手的 H100,內存則增加了 1.7 倍,帶寬增加 1.5 倍。
和上一代一樣,新 GH200 也有着近乎誇張的拓展性。
得益於英偉達的 NVLink 互聯技術, GH200 根據企業的需求組合成不同規模的形態,單卡、雙卡、多卡服務器、機櫃、甚至的超級計算機都沒問題。
最終,GH200 可以組合成 256 張卡的 DGX GH200 SuperPod 超級計算機,擁有了 144 TB 的快速內存,每秒可以執行 10 的 18 次方次浮點運算。
如果這還不能滿足你的需求,還可以用 Nvidia Quantum-2 InfiniBand Switch 交換機讓多個 Nvidia DGX GH200 SuperPod 相連。
老黃打趣説道:「這下應該能帶得動《孤島危機》了。」
強大的拓展性為 GH200 的未來提供無限可能。
換而言之,想要提升運算速度,那麼只需要添置更多的服務器機櫃就能達成。這非常有利於在未來黃仁勳認為,未來 GH200 的典型應用場景就是大語言模型,並且「加速運算」、「AI 運算」將逐漸取代傳統 x86 GPU 的「通用計算」。
舉個例子,過去 1 億美元預算,只能夠建設一個小的數據中心,購買 800 個 x86 GPU,並用 5 兆瓦的電力來運作。
但同樣的預算下,選擇加速計算的 Grace Hopper 只需要消耗 3 兆瓦的電力,而且數據吞吐量還能提高一個數量級。而如果以同樣的工作量來計算,Grace Hopper 計算方案只要 800 萬美元。
説到了這裏,老黃又拋出了他的名言:「你買的越多,省的也就越多。」
官方預計,新款 GH200 需要等到 2024 年的第二季度上市。搭載 HBM3 內存的 GH200 將按原計劃在今年下半年陸續出貨。
當然,對於個人開發者和小團隊來説,要搭建動輒上億的數據中心並不現實,為此英偉達「貼心」地推出了集成先進 RTX 技術的新一代工作站顯卡:NVIDIA RTX 5000 、NVIDIA RTX 4500 以及 NVIDIA RTX 4000。
其中,作為旗艦級別 GPU,NVIDIA RTX 5000 採用了第 4 代 Tensor Core 和第 3 代 RT Core,相比上一代 GPU,單精度浮點運算性能提升了 2 倍,達到了 90 TFLOPS 的峯值,配備高達 32GB 的 GDDR6 視頻內存,支持 ECC 錯誤校驗,適用於高端工作站、數據中心和雲遊戲。
而作為中高端級別 GPU,NVIDIA RTX 4500 配備 24GB GDDR6 視頻內存,也支持 ECC 校驗。
相比前一代產品,NVIDIA RTX 4500 光線追蹤性能提升 1 倍,AI 處理性能提升 2 倍,其性價比非常突出,適合創意專業用户、小型工作站等使用場景。
NVIDIA RTX 4000 則採用了與 RTX 4500 相同的 GPU 核心,配備 20GB GDDR6 視頻內存,其光線追蹤和 AI 計算性能都有大幅提升。
目前全新的 NVIDIA RTX 5000 GPU 已經發售,而 NVIDIA RTX 4500 和 RTX 4000 GPU 將在今年下半年陸續出貨。
最肥沃的「土地」
套用農夫山泉的廣告詞,我們可以這樣介紹英偉達最新的 AI 策略:
眾所周知,本地配置 AI 模型是件繁瑣、複雜的差事,為了幫助開發人員解決這個難題,老黃宣佈,英偉達將推出「AI Workbench」。
簡單來説,AI Workbench 可以一站式地為開發者提供配置 AI 模型所需的框架、工具開發包等環境,直接就可以開始創建項目。
老黃在現場舉了一個非常形象的例子。
比如説,公司需要配置一個 Stable Diffusion 模型來作畫,但是你既沒有硬件設備,又不懂得怎麼配置模型。
不用着急,這時候你只要打開 AI Workbench,選擇一個 4 個 RTX 6000 Ada GPU 的雲工作站,然後就能一鍵配置 Stable Diffusion 模型。
要是你對生成出來的圖片不滿意,你還可以自己上傳圖片,重新訓練模型後再生成。
不用一分鐘,一張像模像樣的圖片就生成出來了,全程你不用操心其他問題,因為 AI Workbench 已經把別的都準備就緒了。
英偉達宣佈,將會與 AI 開源平台 Hugging Face 建立戰略合作關係,將這一技術也被應用到了企業端。
只需在 Hugging Face 平台中簡單點擊幾下,開發者即可輕鬆地將生成式 AI 項目從筆記本電腦到工作站,再轉移到數據中心或雲端,最終藉助 NVIDIA DGX 雲 AI 超級計算資源來訓練 AI 模型。
老黃強調,通過與 Hugging Face 的合作,英偉達最先進的 AI 技術可以為各行各業提供支持。企業也可以利用開源社區的力量,按照企業的規劃需求推進 AI 的訓練。
最宏大的「夢想」
介紹完了軟硬件平台的更新,老黃長吁一口氣説道:「讓我們聊聊今晚最重要的話題——OpenUSD。」
OpenUSD 對大多數人來説應該是一個陌生的名詞。OpenUSD 是皮克斯(是的,拍動畫的那個皮克斯)在 2015 開源的一個框架,在此之前皮克斯已經使用這個框架超過 10 年,我們看過的很多動畫都是基於 OpenUSD 框架製作的。
OpenUSD 可以理解為是一個創建 3D 世界用於描述、組合、模擬和合作的通用標準,老黃將之比作為「HTML 之於 2D 網頁的意義」「真正地把整個世界凝聚了在一起」。
就在上週,皮克斯、 Adobe 、蘋果、 Autodesk、英偉達,以及 JDF 宣佈成立 OpenUSD 聯盟 (AOUSD) ,以促進 OpenUSD 標準化、開發、演變和發展。
為什麼這個名不見經傳的名字能讓這麼多不同領域的巨頭公司聚集在一起?這要從 3D 工作的工作流程説起。
3D 工作流程非常精細且複雜,例如設計師、藝術家和工程師都在 3D 工作流程的某個部分上有所專長,如建模、紋理、材料、物理模擬、動畫、佈景設計和合成等。
由於他們使用的工具(PS、AutoCAD、Blender 等)是由不同的公司開發的,很多文件格式並不能互相兼容,導致用户要頻繁地導出、轉換格式、導入,繁瑣不説還容易損壞內容。
OpenUSD 正是為了解決這些問題而生的技術,通過 OpenUSD,Adobe Stager、Houdini、Maya、Blender、Renderman、Pixar 的 Minuteman 和 Epic 的 Unreal Engine 等工具都能互通數據,發揮出更強大的作用。
隨後,老黃鄭重宣佈英偉達的 Omniverse 將成為第一個完全為 OpenUSD 打造的平台,從底層的數據庫到引擎系統,每一行代碼都是以 OpenUSD 為中心設計的。
不僅如此,英偉達還一同推出了 RunUSD、ChatUSD 和 DeepSearch 等 API,將進一步降低開發者構建基於 OpenUSD 應用的門檻,讓 3D 工作流程可以與 AI 等技術結合起來。
舉個例子,全球最大的廣告公司 WPP 為比亞迪的騰勢 N7 製作的廣告,就是在「元宇宙」拍的。
WPP 把騰勢 N7 的高精 CAD 數據上傳到了 Omniverse 上,製作了一個數字孿生汽車,然後 WPP 的藝術家可以在 Omniverse 的環境裏進行創作。
例如可以調用 ChatUSD API,只需要輸入一句話描述,就能讓 AI 生成不同的背景環境,從而創作出用於全球營銷活動的數千條個性化的內容片段。
元宇宙和生成式 AI 就像是天生一對的搭檔,當兩者相遇後,其價值將會被指數級放大,而 OpenUSD 技術讓這一切變為了可能。
老黃認為,未來還會有越來越多的產業需要經歷數字化轉型,Omniverse 和人工智能即將會成為這些企業們完成數字化轉型時最重要的工作流。
而要搭建 Omniverse 和人工智能,自然離不開強大的算力支持,這便是英偉達真正的形態:
以 GPU 為骨、AI 為膚,組成推動工業數字化轉型最有力的手。
資料來源:愛範兒(ifanr)
五年前,英偉達 CEO 黃仁勳在 2018 SIGGRAPH 發佈了首款支持光線追蹤的顯卡 Quadro RTX,這是英偉達自 G80 以來最重要的產品,把英偉達 GPU 從 GTX 時代推向了 RTX 時代。
彼時,英偉達還是一個非常純粹的圖形計算芯片廠商,滿腦子想的都是怎樣把 3D 渲染推向極致,其市值約為 814 億美元,還沒進入千億俱樂部。

但到了 2023 年,英偉達經歷了脱胎換骨般的鉅變。3 月份的 GTC 大會上,老黃拋出了金句「AI 的 iPhone 時刻已經到了」之後,英偉達的股價便開始節節攀升,不斷刷新歷史新高。
這五年之間,英偉達的股價漲了近 10 倍,當前市值已突破 11000 億,成為全球第一家市值突破萬億美元的芯片公司,也是當前市值僅次於蘋果、微軟、Alphabet、亞馬遜的美股第五大科技股。
英偉達的顯卡在市場上依然搶手,只是現在爭相搶購 GPU 的不再是那羣追求極致畫面的遊戲玩家,而是微軟、Meta 等急着部署和訓練大模型的科技巨頭。
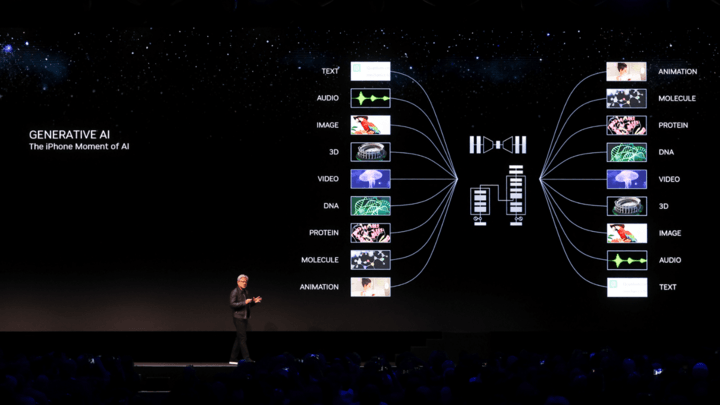
在昨晚的 2023 SIGGRAPH 上,你已經再難聽到老黃説出遊戲、實時渲染、3D 等耳熟能詳的關鍵詞,取而代之的是生成式 AI、數據中心、加速計算等概念。
這是全新的英偉達,也是一個全新的時代。
英偉達變了
我們可以從英偉達的財報解讀這是一家怎麼樣的公司。
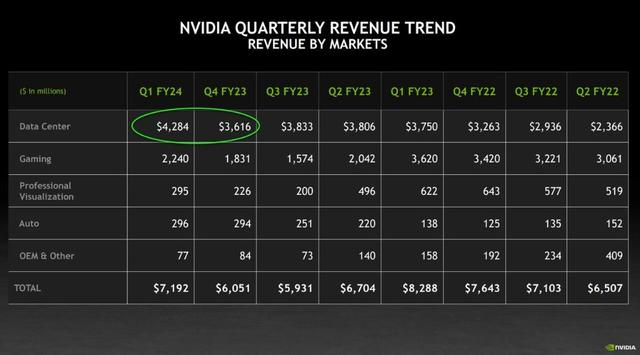
很長一段時間裏,遊戲業務一直是英偉達主營業務,直到 2023 年第一財季,在 PC 市場消費低迷和 AI 計算升温的雙重影響下,英偉達的數據中心業務終於迎頭趕上,成為了英偉達第一收入來源,這也標誌着英偉達正式從傳統的 GPU 供應商轉型成了全球最大的算力供應商之一。
在這之後,英偉達的數據中心開始一路狂飆,其 H100、A100 等計算顯卡成了 AI 行業的硬通貨,一度出現嚴重短缺。有分析師推測,全世界可能需要 43.2 萬張 H100 才能滿足市場需求。
英偉達最新一季的財報顯示,得益於企業們的強烈需求,英偉達的數據中心業務在 Q1 的營收約為 42 億,同比增長了 14%,環比增長了 18%,超出華爾街的預期。

但如果你覺得英偉達只是碰巧被 AI 熱錢砸中的幸運兒,那也太小看老黃了。
對英偉達來説,造「核彈 GPU」、投入 AI,這些不過是實現他們最終願景的所要做的「準備工作」,英偉達真正想要做的,是建設一個真正的元宇宙。
最先進的「鋤頭」
工欲善其事,必先利其器,英偉達深諳此理。

今年 3 月,英偉達發佈了 H100 NVL GPU、L4 Tensor Core GPU、L40 GPU 以和 NVIDIA Grace Hopper 四款 AI 推理芯片,以滿足企業們日益增長的算力需求。
5 月的台北電腦展上,老黃髮布了用 256 個 NVIDIA GH200 Grace Hopper 超級芯片組成的超級計算機 DGX GH200。

而就在昨天,老黃又發佈了搭載 HBM3e 內存新版 GH200,甚至連上一代的 GH200 還沒正式出貨,更新速度快得嚇人。
新舊 GH200 之間的差異主要集中在內存上。
GH200 Grace Hopper 是世界上首個搭載 HBM3e 內存的 GPU 芯片,內存容量從每個 GPU 96 GB 擴展到 144 GB,增加了 50% 。
HBM3e 內存是一種新型的高帶寬內存技術,在運算速度上 HBM3e 能比 HBM3 運算速度快 50%,提供最高 5TB/秒的傳輸速率。 這讓新版本的 GH200 運行 AI 模型的速度比當前模型快 3.5 倍。
其中,雙配置的 GH200 內存能達到 282 GB 的 HBM3e 內存,相比上一代的容量增加了 3.5 倍,帶寬增加了 3 倍。相比搶手的 H100,內存則增加了 1.7 倍,帶寬增加 1.5 倍。
和上一代一樣,新 GH200 也有着近乎誇張的拓展性。

得益於英偉達的 NVLink 互聯技術, GH200 根據企業的需求組合成不同規模的形態,單卡、雙卡、多卡服務器、機櫃、甚至的超級計算機都沒問題。

最終,GH200 可以組合成 256 張卡的 DGX GH200 SuperPod 超級計算機,擁有了 144 TB 的快速內存,每秒可以執行 10 的 18 次方次浮點運算。
如果這還不能滿足你的需求,還可以用 Nvidia Quantum-2 InfiniBand Switch 交換機讓多個 Nvidia DGX GH200 SuperPod 相連。
老黃打趣説道:「這下應該能帶得動《孤島危機》了。」
強大的拓展性為 GH200 的未來提供無限可能。
換而言之,想要提升運算速度,那麼只需要添置更多的服務器機櫃就能達成。這非常有利於在未來黃仁勳認為,未來 GH200 的典型應用場景就是大語言模型,並且「加速運算」、「AI 運算」將逐漸取代傳統 x86 GPU 的「通用計算」。

舉個例子,過去 1 億美元預算,只能夠建設一個小的數據中心,購買 800 個 x86 GPU,並用 5 兆瓦的電力來運作。
但同樣的預算下,選擇加速計算的 Grace Hopper 只需要消耗 3 兆瓦的電力,而且數據吞吐量還能提高一個數量級。而如果以同樣的工作量來計算,Grace Hopper 計算方案只要 800 萬美元。
説到了這裏,老黃又拋出了他的名言:「你買的越多,省的也就越多。」
官方預計,新款 GH200 需要等到 2024 年的第二季度上市。搭載 HBM3 內存的 GH200 將按原計劃在今年下半年陸續出貨。

當然,對於個人開發者和小團隊來説,要搭建動輒上億的數據中心並不現實,為此英偉達「貼心」地推出了集成先進 RTX 技術的新一代工作站顯卡:NVIDIA RTX 5000 、NVIDIA RTX 4500 以及 NVIDIA RTX 4000。
其中,作為旗艦級別 GPU,NVIDIA RTX 5000 採用了第 4 代 Tensor Core 和第 3 代 RT Core,相比上一代 GPU,單精度浮點運算性能提升了 2 倍,達到了 90 TFLOPS 的峯值,配備高達 32GB 的 GDDR6 視頻內存,支持 ECC 錯誤校驗,適用於高端工作站、數據中心和雲遊戲。

而作為中高端級別 GPU,NVIDIA RTX 4500 配備 24GB GDDR6 視頻內存,也支持 ECC 校驗。
相比前一代產品,NVIDIA RTX 4500 光線追蹤性能提升 1 倍,AI 處理性能提升 2 倍,其性價比非常突出,適合創意專業用户、小型工作站等使用場景。
NVIDIA RTX 4000 則採用了與 RTX 4500 相同的 GPU 核心,配備 20GB GDDR6 視頻內存,其光線追蹤和 AI 計算性能都有大幅提升。
目前全新的 NVIDIA RTX 5000 GPU 已經發售,而 NVIDIA RTX 4500 和 RTX 4000 GPU 將在今年下半年陸續出貨。
最肥沃的「土地」
套用農夫山泉的廣告詞,我們可以這樣介紹英偉達最新的 AI 策略:
引用我們不生產 AI,我們只是 AI 的搬運工。
眾所周知,本地配置 AI 模型是件繁瑣、複雜的差事,為了幫助開發人員解決這個難題,老黃宣佈,英偉達將推出「AI Workbench」。
簡單來説,AI Workbench 可以一站式地為開發者提供配置 AI 模型所需的框架、工具開發包等環境,直接就可以開始創建項目。
老黃在現場舉了一個非常形象的例子。
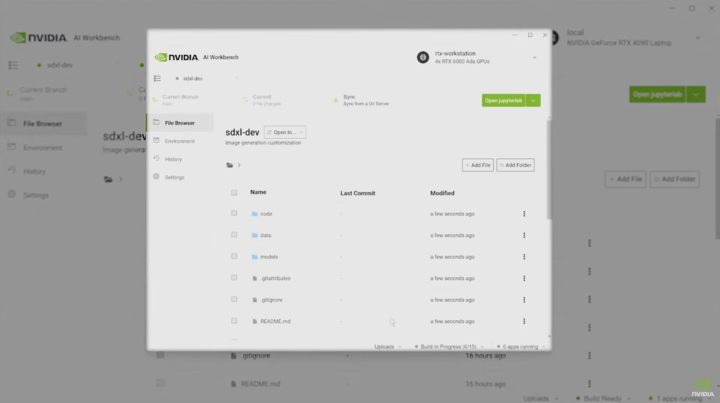
比如説,公司需要配置一個 Stable Diffusion 模型來作畫,但是你既沒有硬件設備,又不懂得怎麼配置模型。
不用着急,這時候你只要打開 AI Workbench,選擇一個 4 個 RTX 6000 Ada GPU 的雲工作站,然後就能一鍵配置 Stable Diffusion 模型。

要是你對生成出來的圖片不滿意,你還可以自己上傳圖片,重新訓練模型後再生成。
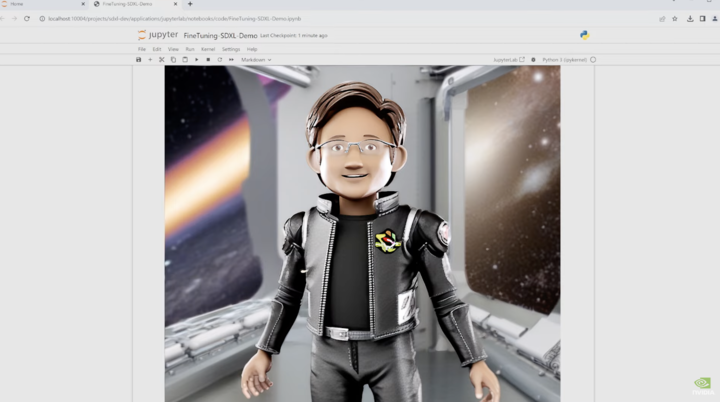
不用一分鐘,一張像模像樣的圖片就生成出來了,全程你不用操心其他問題,因為 AI Workbench 已經把別的都準備就緒了。

英偉達宣佈,將會與 AI 開源平台 Hugging Face 建立戰略合作關係,將這一技術也被應用到了企業端。
只需在 Hugging Face 平台中簡單點擊幾下,開發者即可輕鬆地將生成式 AI 項目從筆記本電腦到工作站,再轉移到數據中心或雲端,最終藉助 NVIDIA DGX 雲 AI 超級計算資源來訓練 AI 模型。
老黃強調,通過與 Hugging Face 的合作,英偉達最先進的 AI 技術可以為各行各業提供支持。企業也可以利用開源社區的力量,按照企業的規劃需求推進 AI 的訓練。
最宏大的「夢想」
介紹完了軟硬件平台的更新,老黃長吁一口氣説道:「讓我們聊聊今晚最重要的話題——OpenUSD。」

OpenUSD 對大多數人來説應該是一個陌生的名詞。OpenUSD 是皮克斯(是的,拍動畫的那個皮克斯)在 2015 開源的一個框架,在此之前皮克斯已經使用這個框架超過 10 年,我們看過的很多動畫都是基於 OpenUSD 框架製作的。

OpenUSD 可以理解為是一個創建 3D 世界用於描述、組合、模擬和合作的通用標準,老黃將之比作為「HTML 之於 2D 網頁的意義」「真正地把整個世界凝聚了在一起」。

就在上週,皮克斯、 Adobe 、蘋果、 Autodesk、英偉達,以及 JDF 宣佈成立 OpenUSD 聯盟 (AOUSD) ,以促進 OpenUSD 標準化、開發、演變和發展。
為什麼這個名不見經傳的名字能讓這麼多不同領域的巨頭公司聚集在一起?這要從 3D 工作的工作流程説起。
3D 工作流程非常精細且複雜,例如設計師、藝術家和工程師都在 3D 工作流程的某個部分上有所專長,如建模、紋理、材料、物理模擬、動畫、佈景設計和合成等。
由於他們使用的工具(PS、AutoCAD、Blender 等)是由不同的公司開發的,很多文件格式並不能互相兼容,導致用户要頻繁地導出、轉換格式、導入,繁瑣不説還容易損壞內容。
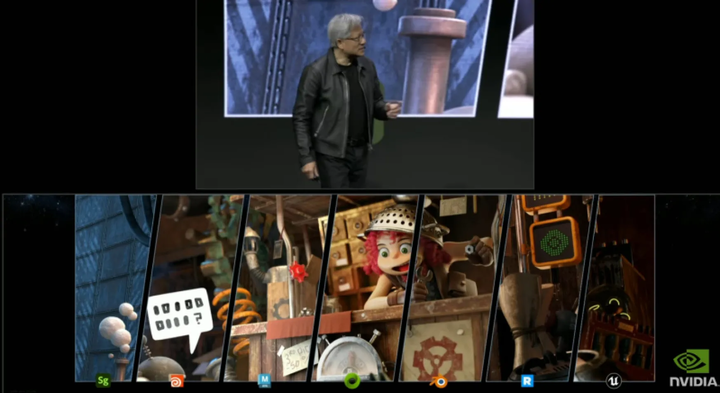
OpenUSD 正是為了解決這些問題而生的技術,通過 OpenUSD,Adobe Stager、Houdini、Maya、Blender、Renderman、Pixar 的 Minuteman 和 Epic 的 Unreal Engine 等工具都能互通數據,發揮出更強大的作用。
隨後,老黃鄭重宣佈英偉達的 Omniverse 將成為第一個完全為 OpenUSD 打造的平台,從底層的數據庫到引擎系統,每一行代碼都是以 OpenUSD 為中心設計的。
不僅如此,英偉達還一同推出了 RunUSD、ChatUSD 和 DeepSearch 等 API,將進一步降低開發者構建基於 OpenUSD 應用的門檻,讓 3D 工作流程可以與 AI 等技術結合起來。
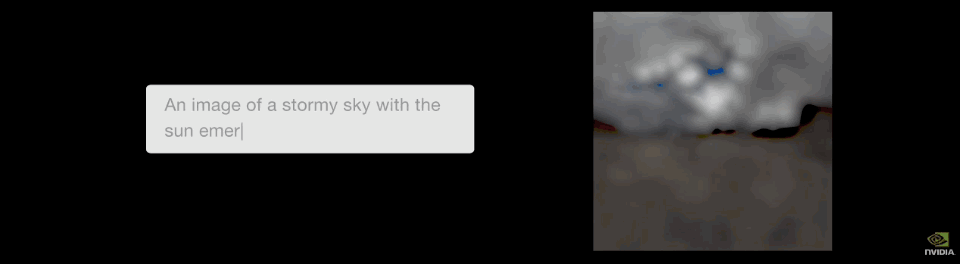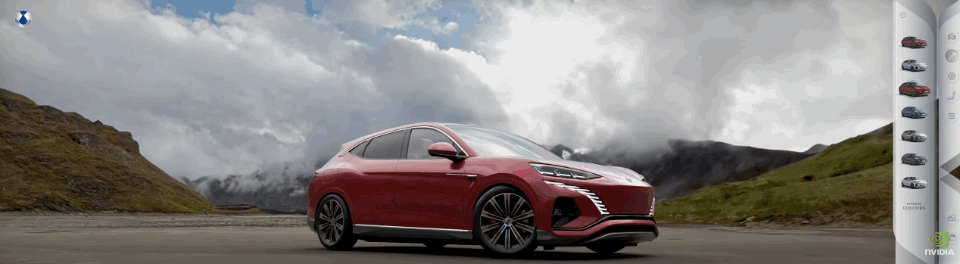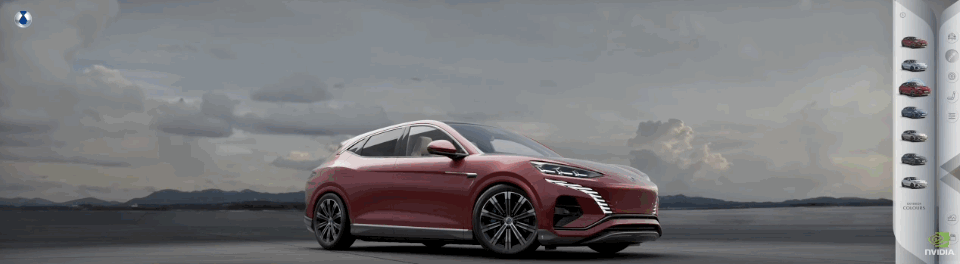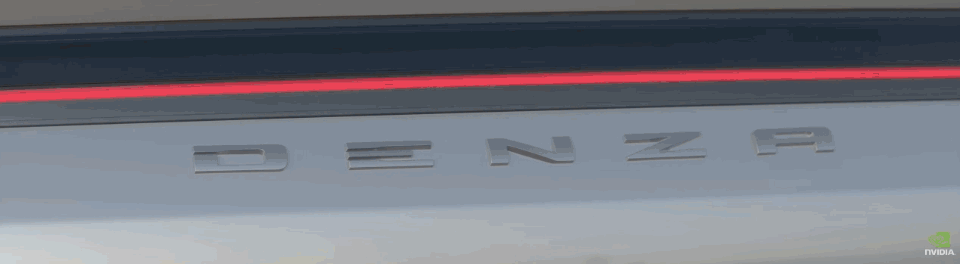
舉個例子,全球最大的廣告公司 WPP 為比亞迪的騰勢 N7 製作的廣告,就是在「元宇宙」拍的。
WPP 把騰勢 N7 的高精 CAD 數據上傳到了 Omniverse 上,製作了一個數字孿生汽車,然後 WPP 的藝術家可以在 Omniverse 的環境裏進行創作。
例如可以調用 ChatUSD API,只需要輸入一句話描述,就能讓 AI 生成不同的背景環境,從而創作出用於全球營銷活動的數千條個性化的內容片段。
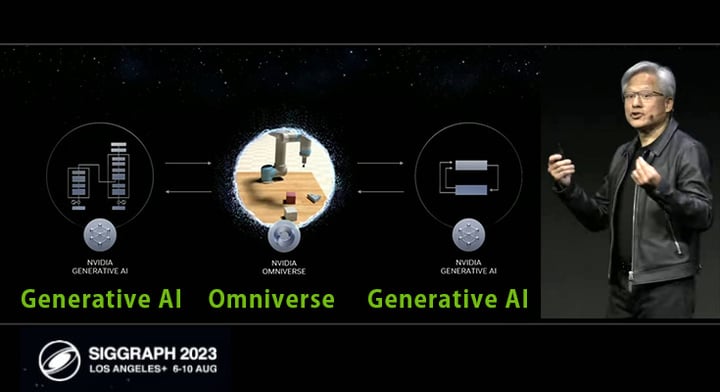
元宇宙和生成式 AI 就像是天生一對的搭檔,當兩者相遇後,其價值將會被指數級放大,而 OpenUSD 技術讓這一切變為了可能。
老黃認為,未來還會有越來越多的產業需要經歷數字化轉型,Omniverse 和人工智能即將會成為這些企業們完成數字化轉型時最重要的工作流。
而要搭建 Omniverse 和人工智能,自然離不開強大的算力支持,這便是英偉達真正的形態:
以 GPU 為骨、AI 為膚,組成推動工業數字化轉型最有力的手。
資料來源:愛範兒(ifanr)