OpenAI 用 26 分鐘改變世界!免費版 GPT-4 來了,視頻語音交互快進到科幻片
今天凌晨,一場 26 分鐘的發佈會,將又一次大大改變 AI 行業和我們未來的生活,也會讓無數 AI 初創公司焦頭爛額。
這真不是標題黨,因為這是 OpenAI 的發佈會。
剛剛,OpenAI 正式發佈了 GPT-4o,其中的「o」代表「omni」(即全面、全能的意思),這個模型同時具備文本、圖片、視頻和語音方面的能力,這甚至就是 GPT-5 的一個未完成版。
更重要的是,這個 GPT-4 級別的模型,將向所有用户免費提供,並將在未來幾周內向 ChatGPT Plus 推出。
我們先給大家一次性總結這場發佈會的亮點,更多功能解析請接着往下看。
發佈會要點
這些功能早在預熱階段就被 Altman 形容為「感覺像魔法」。既然全世界 AI 模型都在「趕超 GPT-4」,那 OpenAI 也要從武器庫掏出點真傢伙。
免費可用的 GPT-4o 來了,但這不是它最大的亮點
其實在發佈會前一天,我們發現 OpenAI 已經悄悄將 GPT-4 的描述從「最先進的模型」,修改為「先進的」。
這就是為了迎接 GPT-4o 的到來。GPT-4o 的強大在於,可以接受任何文本、音頻和圖像的組合作為輸入,並直接生成上述這幾種媒介輸出。
這意味着人機交互將更接近人與人的自然交流。
GPT-4o 可以在 232 毫秒內迴應音頻輸入,平均為 320 毫秒,這接近於人類對話的反應時間。此前使用語音模式與 ChatGPT 進行交流,平均延遲為 2.8 秒(GPT-3.5)和 5.4 秒(GPT-4)。
它在英文和代碼文本上與 GPT-4 Turbo 的性能相匹敵,在非英語語言文本上有顯著改進,同時在 API 上更快速且價格便宜 50%。
而與現有模型相比,GPT-4o 在視覺和音頻理解方面表現尤為出色。
從測試參數來看,GPT-4o 主要能力上基本和目前最強 OpenAI 的 GPT-4 Turbo 處於一個水平。
[圖片]
[圖片]
[圖片]
過去我們和 Siri 或其他語音助手的使用體驗都不夠理想,本質上是因為語音助手對話要經歷三個階段:
然而我們日常的自然對話基本上卻是這樣的
此前的 AI 語言助手無法很好處理這些問題,在對話的三個階段每一步都有較大延遲,因此體驗不佳。同時會在過程中丟失很多信息,比如無法直接觀察語調、多個説話者或背景噪音,也無法輸出笑聲、歌唱或表達情感。
當音頻能直接生成音頻、圖像、文字、視頻,整個體驗將是跨越式的。
GPT-4o 就是 OpenAI 為此而訓練的一個全新的模型,而要時間跨越文本、視頻和音頻的直接轉換,這要求所有的輸入和輸出都由同一個神經網絡處理。
而更令人驚喜的是,ChatGPT 免費用户就能使用 GPT-4o 可以體驗以下功能:
而當你看完 GPT-4o 下面這些演示,你的感受或許將更加複雜。
ChatGPT 版「賈維斯」,人人都有
ChatGPT 不光能説,能聽,還能看,這已經不是什麼新鮮事了,但「船新版本」的 ChatGPT 還是驚豔到我了。
睡覺搭子
以一個具體的生活場景為例,讓 ChatGPT 講一個關於機器人和愛的睡前故事,它幾乎不用太多思考,張口就能説出一個帶有情感和戲劇性的睡前故事。
甚至它還能以唱歌的形式來講述故事,簡直可以充當用户的睡眠搭子。
做題高手
又或者,在發佈會現場,讓其演示如何給線性方程 3X+1=4 的求解提供幫助,它能夠一步步貼心地引導並給出正確答案。
當然,上述還是一些「小兒戲」,現場的編碼難題才是真正的考驗。不過,三下五除二的功夫,它都能輕鬆解決。
藉助 ChatGPT 的「視覺」,它能夠查看電腦屏幕上的一切,譬如與代碼庫交互並查看代碼生成的圖表,咦,不對勁?那我們以後的隱私豈不是也要被看得一清二楚了?
實時翻譯
現場的觀眾也給 ChatGPT 提出了一些刁鑽的問題。
從英語翻譯到意大利語,從意大利語翻譯到英語,無論怎麼折騰該 AI 語音助手,它都遊刃有餘,看來沒必要花大價錢去買翻譯機了,在未來,指不定 ChatGPT 可能比你的實時翻譯機還靠譜。
暫時無法在飛書文檔外展示此內容
▲ 實時翻譯(官網案例)
感知語言的情緒還只是第一步,ChatGPT 還能解讀人類的的面部情緒。
在發佈會現場,面對攝像頭拍攝的人臉,ChatGPT 直接將其「誤認為」桌子,正當大傢伙以為要翻車時,原來是因為最先打開的前置攝像頭瞄準了桌子。
不過,最後它還是準確描述出自拍面部的情緒,並且準確識別出臉上的「燦爛」的笑臉。
有趣的是,在發佈會的尾聲,發言人也不忘 Cue 了英偉達和其創始人老黃的「鼎力支持」,屬實是懂人情世故的。
Altman 在此前的採訪中表示希望最終開發出一種類似於 AI 電影《Her》中的 AI 助理,而今天 OpenAI 發佈的語音助手切實是有走進現實那味了。
OpenAI 的首席運營官 Brad Lightcap 前不久曾預測,未來我們會像人類交談一樣與 AI 聊天機器人對話,將其視為團隊中的一員。
現在看來,這不僅為今天的發佈會埋下了伏筆,同時也是我們未來十年生活的生動註腳。
蘋果在 AI 語音助手「兜兜轉轉」了十三年的時間都沒能走出迷宮,而 OpenAI 一夜之間就找到出口。可預見的是,在不久的將來,鋼鐵俠的「賈維斯」將不再是幻想。
《她》來了
雖然 Sam Altman 沒在發佈會上出現,但他在發佈會後就發佈了一篇博客,並且在 X 上發了一個詞: her。
這顯然在暗指那部同名的經典科幻電影《她》,這樣是我觀看這場發佈會的演示時,腦子裏最先聯想的畫面。
電影《她》裏的薩曼莎,不只是產品,甚至比人類更懂人類,也更像人類自己 ,你真的能在和她的交流中逐漸忘記,她原來是一個 AI 。
這意味着人機交互模式可能迎來圖像界面後真正的革命性更新,如同 Sam Altman 在博客中表示:
之前的 ChatGPT 讓我們看到自然用户界面初露端倪:簡單性高於一切:複雜性是自然用户界面的敵人。每個交互都應該是不言自明的,不需要説明手冊。
但今天發佈的 GPT-4o 則完全不同,它的幾乎無延遲的相應、聰明、有趣、且實用,我們和計算機的交互從未真正體驗過這樣的自然順暢。
這裏面還藏着巨大可能性,當支持更多的個性化功能和與不同終端設備的協同後,意味着我們能夠利用手機、電腦、智能眼鏡等計算終端做到很多以往無法實現的事情。
AI 硬件不會再試積累,當下更令人期待的,就是如果下個月蘋果 WWDC 真的官宣與 OpenAI 達成合作,那麼 iPhone 的體驗提升或許將比近幾年任何一次發佈會都大。
英偉達高級可科學家 Jim Fan 認為,號稱史上最大更新 iOS 18 ,和 OpenAI 的合作可能會有三個層面:
説到這裏,也不得不心疼明天要舉辦發佈會的 Google 一秒。
作者:李超凡 莫崇宇
資料來源:愛範兒(ifanr)
這真不是標題黨,因為這是 OpenAI 的發佈會。
剛剛,OpenAI 正式發佈了 GPT-4o,其中的「o」代表「omni」(即全面、全能的意思),這個模型同時具備文本、圖片、視頻和語音方面的能力,這甚至就是 GPT-5 的一個未完成版。
更重要的是,這個 GPT-4 級別的模型,將向所有用户免費提供,並將在未來幾周內向 ChatGPT Plus 推出。
我們先給大家一次性總結這場發佈會的亮點,更多功能解析請接着往下看。

發佈會要點
- 新的 GPT-4o 模型:打通任何文本、音頻和圖像的輸入,相互之間可以直接生成,無需中間轉換
- GPT-4o 語音延遲大幅降低,能在 232 毫秒內迴應音頻輸入,平均為 320 毫秒,這與對話中人類的響應時間相似。
- GPT-4 向所有用户免費開放
- GPT-4o API,比 GPT4-turbo 快 2 倍,價格便宜 50%
- 驚豔的實時語音助手演示:對話更像人、能實時翻譯,識別表情,可以通過攝像頭識別畫面寫代碼分析圖表
- ChatGPT 新 UI,更簡潔
- 一個新的 ChatGPT 桌面應用程序,適用於 macOS,Windows 版本今年晚些時候推出
這些功能早在預熱階段就被 Altman 形容為「感覺像魔法」。既然全世界 AI 模型都在「趕超 GPT-4」,那 OpenAI 也要從武器庫掏出點真傢伙。
免費可用的 GPT-4o 來了,但這不是它最大的亮點
其實在發佈會前一天,我們發現 OpenAI 已經悄悄將 GPT-4 的描述從「最先進的模型」,修改為「先進的」。
這就是為了迎接 GPT-4o 的到來。GPT-4o 的強大在於,可以接受任何文本、音頻和圖像的組合作為輸入,並直接生成上述這幾種媒介輸出。
這意味着人機交互將更接近人與人的自然交流。
GPT-4o 可以在 232 毫秒內迴應音頻輸入,平均為 320 毫秒,這接近於人類對話的反應時間。此前使用語音模式與 ChatGPT 進行交流,平均延遲為 2.8 秒(GPT-3.5)和 5.4 秒(GPT-4)。
它在英文和代碼文本上與 GPT-4 Turbo 的性能相匹敵,在非英語語言文本上有顯著改進,同時在 API 上更快速且價格便宜 50%。

而與現有模型相比,GPT-4o 在視覺和音頻理解方面表現尤為出色。
- 你在對話時可以隨時打斷
- 可以根據場景生成多種音調,帶有人類般的情緒和情感
- 直接通過和 AI 視頻通話讓它在線解答各種問題
從測試參數來看,GPT-4o 主要能力上基本和目前最強 OpenAI 的 GPT-4 Turbo 處於一個水平。
[圖片]
[圖片]
[圖片]
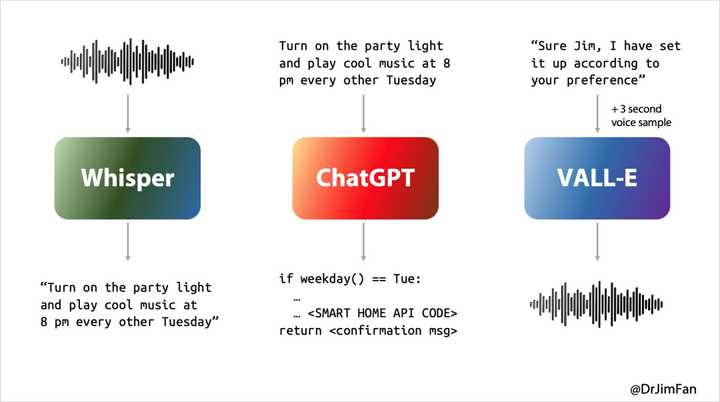
過去我們和 Siri 或其他語音助手的使用體驗都不夠理想,本質上是因為語音助手對話要經歷三個階段:
- 語音識別或「ASR」:音頻 -> 文本,類似 Whisper;
- LLM 計劃下一步要説什麼:文本 1 -> 文本 2;
- 語音合成或「TTS」:文本 2 -> 音頻,想象 ElevenLabs 或 VALL-E。
然而我們日常的自然對話基本上卻是這樣的
- 在聽和説的同時考慮下一步要説什麼;
- 在適當的時刻插入「是的,嗯,嗯」;
- 預測對方講話結束的時間,並立即接管;
- 自然地決定打斷對方的談話,而不會引起反感;
- 在聽和説的同時考慮下一步要説什麼;
- 在適當的時刻插入「是的,嗯,嗯」;
- 優雅地處理並打斷。
此前的 AI 語言助手無法很好處理這些問題,在對話的三個階段每一步都有較大延遲,因此體驗不佳。同時會在過程中丟失很多信息,比如無法直接觀察語調、多個説話者或背景噪音,也無法輸出笑聲、歌唱或表達情感。

當音頻能直接生成音頻、圖像、文字、視頻,整個體驗將是跨越式的。
GPT-4o 就是 OpenAI 為此而訓練的一個全新的模型,而要時間跨越文本、視頻和音頻的直接轉換,這要求所有的輸入和輸出都由同一個神經網絡處理。
而更令人驚喜的是,ChatGPT 免費用户就能使用 GPT-4o 可以體驗以下功能:
- 體驗 GPT-4 級別的智能
- 從模型和網絡獲取響應
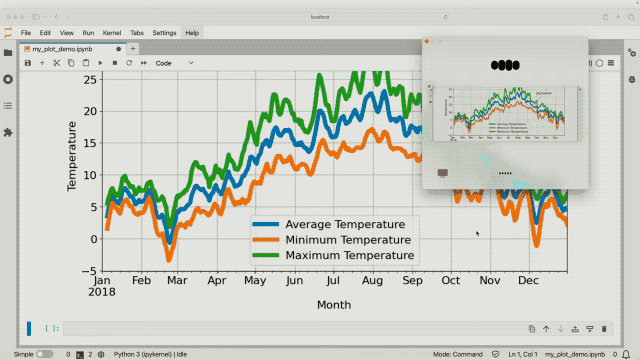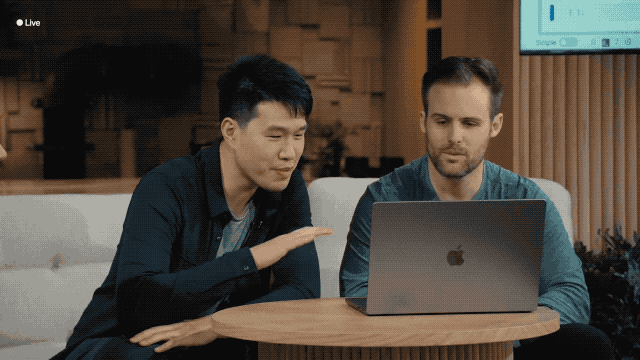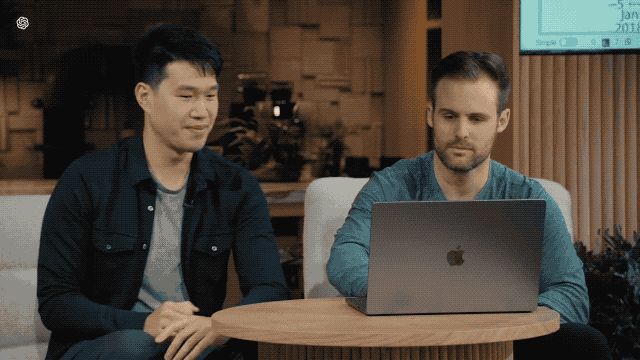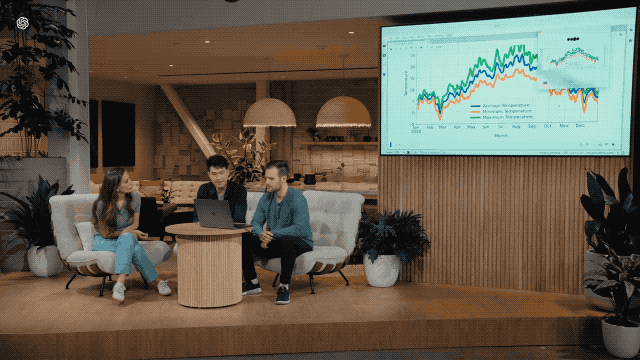
- 分析數據並創建圖表
- 聊一聊你拍的照片
- 上傳文件以獲取摘要、寫作或分析幫助
- 使用 GPTs 和 GPT Store
- 通過 Memory 構建更加有幫助的體驗
而當你看完 GPT-4o 下面這些演示,你的感受或許將更加複雜。
ChatGPT 版「賈維斯」,人人都有
ChatGPT 不光能説,能聽,還能看,這已經不是什麼新鮮事了,但「船新版本」的 ChatGPT 還是驚豔到我了。
睡覺搭子
以一個具體的生活場景為例,讓 ChatGPT 講一個關於機器人和愛的睡前故事,它幾乎不用太多思考,張口就能説出一個帶有情感和戲劇性的睡前故事。
甚至它還能以唱歌的形式來講述故事,簡直可以充當用户的睡眠搭子。
做題高手

又或者,在發佈會現場,讓其演示如何給線性方程 3X+1=4 的求解提供幫助,它能夠一步步貼心地引導並給出正確答案。
當然,上述還是一些「小兒戲」,現場的編碼難題才是真正的考驗。不過,三下五除二的功夫,它都能輕鬆解決。
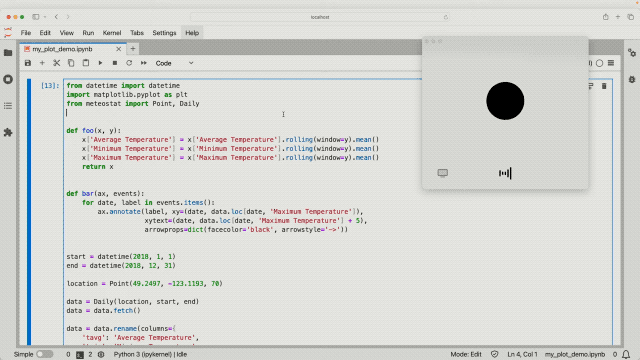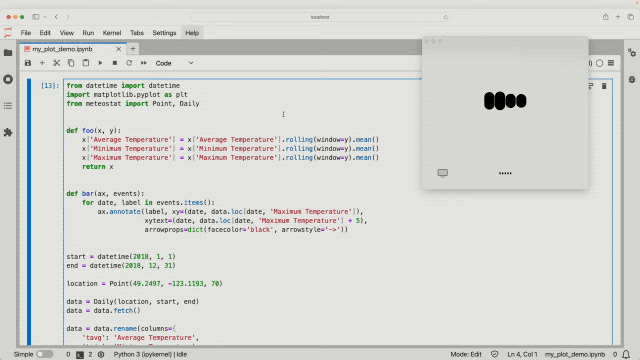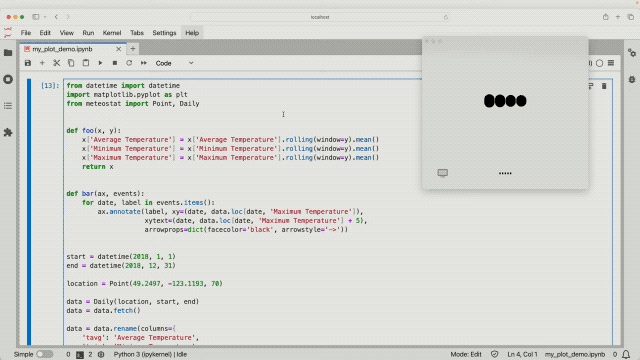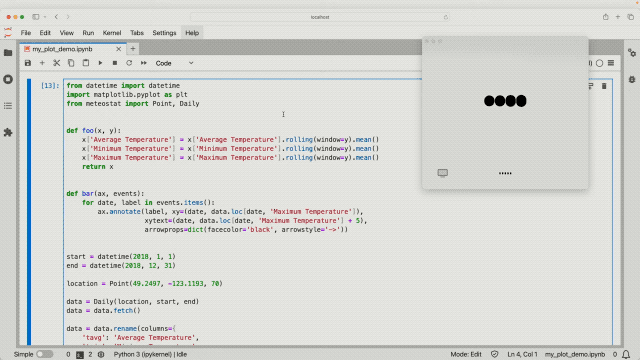
藉助 ChatGPT 的「視覺」,它能夠查看電腦屏幕上的一切,譬如與代碼庫交互並查看代碼生成的圖表,咦,不對勁?那我們以後的隱私豈不是也要被看得一清二楚了?
實時翻譯
現場的觀眾也給 ChatGPT 提出了一些刁鑽的問題。
從英語翻譯到意大利語,從意大利語翻譯到英語,無論怎麼折騰該 AI 語音助手,它都遊刃有餘,看來沒必要花大價錢去買翻譯機了,在未來,指不定 ChatGPT 可能比你的實時翻譯機還靠譜。
暫時無法在飛書文檔外展示此內容
▲ 實時翻譯(官網案例)
感知語言的情緒還只是第一步,ChatGPT 還能解讀人類的的面部情緒。

在發佈會現場,面對攝像頭拍攝的人臉,ChatGPT 直接將其「誤認為」桌子,正當大傢伙以為要翻車時,原來是因為最先打開的前置攝像頭瞄準了桌子。
不過,最後它還是準確描述出自拍面部的情緒,並且準確識別出臉上的「燦爛」的笑臉。
有趣的是,在發佈會的尾聲,發言人也不忘 Cue 了英偉達和其創始人老黃的「鼎力支持」,屬實是懂人情世故的。
引用對話語言界面的想法具有令人難以置信的預見性。
Altman 在此前的採訪中表示希望最終開發出一種類似於 AI 電影《Her》中的 AI 助理,而今天 OpenAI 發佈的語音助手切實是有走進現實那味了。
OpenAI 的首席運營官 Brad Lightcap 前不久曾預測,未來我們會像人類交談一樣與 AI 聊天機器人對話,將其視為團隊中的一員。

現在看來,這不僅為今天的發佈會埋下了伏筆,同時也是我們未來十年生活的生動註腳。
蘋果在 AI 語音助手「兜兜轉轉」了十三年的時間都沒能走出迷宮,而 OpenAI 一夜之間就找到出口。可預見的是,在不久的將來,鋼鐵俠的「賈維斯」將不再是幻想。
《她》來了
雖然 Sam Altman 沒在發佈會上出現,但他在發佈會後就發佈了一篇博客,並且在 X 上發了一個詞: her。
這顯然在暗指那部同名的經典科幻電影《她》,這樣是我觀看這場發佈會的演示時,腦子裏最先聯想的畫面。
電影《她》裏的薩曼莎,不只是產品,甚至比人類更懂人類,也更像人類自己 ,你真的能在和她的交流中逐漸忘記,她原來是一個 AI 。

這意味着人機交互模式可能迎來圖像界面後真正的革命性更新,如同 Sam Altman 在博客中表示:
引用新的語音(和視頻)模式是我使用過的最好的計算機界面。它感覺像電影中的人工智能;而且我仍然有點驚訝它是真實的。達到人類級別的響應時間和表現力原來是一個很大的改變。
之前的 ChatGPT 讓我們看到自然用户界面初露端倪:簡單性高於一切:複雜性是自然用户界面的敵人。每個交互都應該是不言自明的,不需要説明手冊。
但今天發佈的 GPT-4o 則完全不同,它的幾乎無延遲的相應、聰明、有趣、且實用,我們和計算機的交互從未真正體驗過這樣的自然順暢。
這裏面還藏着巨大可能性,當支持更多的個性化功能和與不同終端設備的協同後,意味着我們能夠利用手機、電腦、智能眼鏡等計算終端做到很多以往無法實現的事情。
AI 硬件不會再試積累,當下更令人期待的,就是如果下個月蘋果 WWDC 真的官宣與 OpenAI 達成合作,那麼 iPhone 的體驗提升或許將比近幾年任何一次發佈會都大。
英偉達高級可科學家 Jim Fan 認為,號稱史上最大更新 iOS 18 ,和 OpenAI 的合作可能會有三個層面:
- 放棄 Siri,OpenAI 為 iOS 提煉出一個純粹在設備上運行的小型 GPT-4o,可選擇付費升級使用雲服務。
- 原生功能將攝像頭或屏幕流輸入到模型中。芯片級支持神經音視頻編解碼器。
- 與 iOS 系統級操作 API 和智能家居 API 集成。沒有人使用 Siri 快捷方式,但是是時候復興了。這可能會成為一開始就擁有十億用户的 AI 代理產品。這對智能手機來説,就像特斯拉那樣的全尺寸數據飛輪。
説到這裏,也不得不心疼明天要舉辦發佈會的 Google 一秒。
作者:李超凡 莫崇宇
資料來源:愛範兒(ifanr)