被馬斯克炮轟的 Apple 智能,為什麼更接近理想的 AI 形態?
今年的蘋果 WWDC,是一場事先張揚的 AI 發佈會,庫克罕見地從幾個月前就在各種場合渲染氣氛。
可當你上個月看過 OpenAI 和 Google 、微軟的發佈會,又會覺得這不像一場 AI 發佈會。
蘋果甚至沒有正式發佈一款大模型,沒有對比友商參數量、多模態能力這些常規環節,沒談 AGI 的未來,也沒有祭出像 Copilot 這種被媒體高呼「顛覆一切」的爆款應用。
蘋果反而造了一個叫 Apple Intelligence(下稱「Apple 智能」)的詞,這個諧音梗是在告訴人們,蘋果發佈的不是一款軟件或硬件,而是一種新的用户體驗。
庫克認為 AI 必須以用户為中心,需要無縫集成到你日常使用的體驗中:
而 Apple 智能,是在給 AI 應用鋪墊一種新的敍事,這可能不只是蘋果的新篇章。
個人智能和個人隱私
在 Apple 智能亮相時,蘋果就總結了它的五個特點:強大、易用、深度整合、個人化、私人化。
要想讓 AI 融合生活細節,甚至不被察覺,得讓 AI 甚至比你還了解你自己。這也意味着你的個人數據越多,就越可能實現,隨後不能不面對的問題就是:這是否要建立在讓渡個人隱私的基礎上實現?
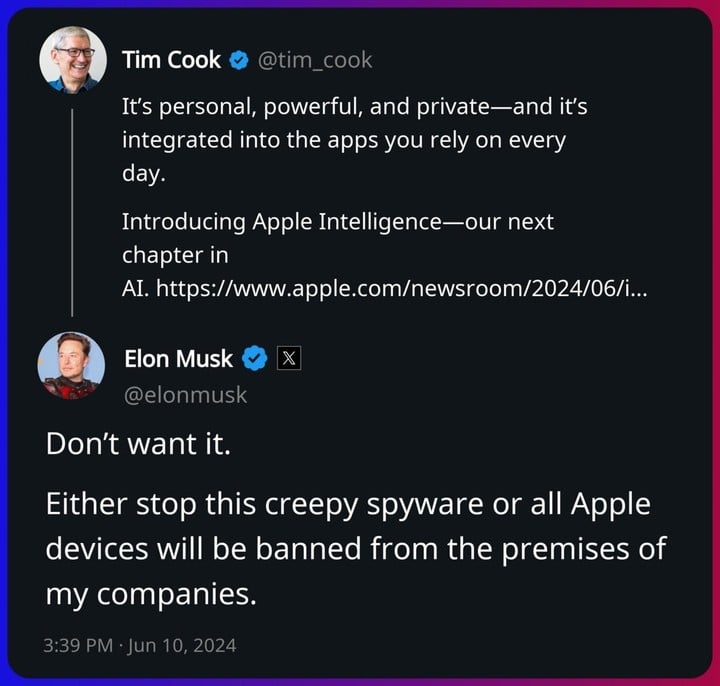
這也是今天發佈會後,馬斯克批評蘋果的由來。
他甚至直接在庫克的推文下表示「要禁止所有蘋果設備進入我公司的辦公場所」,並對蘋果和 OpenAI 合作後用户隱私安全的保護提出質疑。
其實這也的確是用户會擔憂的問題,尤其對於活躍設備高達 22 億的蘋果。但這也和蘋果對隱私保護一向慎重的行事風格相悖。
過去蘋果設備和 AI 相關的功能基本都是依靠本地機器學習實現的,所需的數據量很少,很大程度上就是基於對個人隱私的考慮。
雖然蘋果在發佈會上對這些問題沒有一一介紹,但我們通過會後的一些媒體分享會,也瞭解到更多 Apple 智能在隱私方面的處理方式,可以試着釐清目前網絡上爭議較大的一些問題。
APPSO 獲悉,蘋果針對涉及雲端的數據處理提供了兩個新的解決方案。
首先,用户不必將所有數據、所有郵件、所有消息、所有照片、所有文檔發送到別人的雲端並存儲在那裏,以便服務器模型在需要時可以探測它們。
相反,用户的設備上的 Apple 智能會找出哪些小部分信息與回答這個問題相關。因此,向雲端提出的問題只包含這些小部分信息,而蘋果對小部分信息再進行保密處理。
蘋果創建了一個加密系統,比如 iPhone 只能與帶有指定標籤的服務器通信。換句話説,如果這台服務器上的軟件有任何更改,其簽名也會隨之改變,而你可以拒絕與其通信。
包括和 OpenAI 合作的用户數據處理也是,擁有註冊賬號的用户 IP 地址在使用服務時會被隱藏掉,OpenAI 也不被允許記錄用户請求。
這或許會在一定程度解答公眾的疑惑,蘋果也的確有必要在這方面披露更多信息。強調「個人化」的 Apple 智能,要實現發佈會上的藍圖,這是必須要處理好的問題。
而且蘋果和 OpenAI 的合作模式很可能並非獨家,未來在不同的場景,不同的地區,顯然是保留了其他大模型合作的空間。
這也並非蘋果一家廠商要面臨的問題,但無論是誰都必須慎重挑選合作伙伴,當 AI 隨着大量終端設備滲透生活,隱私和便利的交鋒會愈加激烈,即便被認為是忍受度更高的中國市場亦是如此。
一場沒有硬件的發佈會,卻對硬件影響很大
Apple 智能從命名到實現方式,都看出蘋果要以自己的方式來定義 AI 硬件,將 AI 能力滲透到整個生態之中,而不是推出某一個殺手級應用和功能。
這是和目前大量 AI 硬件最大的不同,去年開始硬件廠商掀起了 AI 硬件的潮流。當中不少都是將 AI 硬件簡單等同於大模型+終端設備,結果就是推出的往往是某個功能,更新實驗性質的半成品。
這也是 Ai Pin 和 Rabbit R1 等網紅 AI 硬件熱鬧一波就折戟沉沙的重要原因。
Apple 智能的思路和過去機器學習在蘋果產品的應用方式類似,儘管蘋果不怎麼提 AI ,但已經融入到很多常用的小功能,比如 AirPods Pro 自適應音頻模式也是通過機器學習實現。
很多人説在大模型時代蘋果已經掉隊,從單一技術上來説很可能的確如此,但蘋果需要的從來不是一個比 ChatGPT 更牛逼的模型,而是將算力轉化為整體而非局部的體驗。
雖然這場發佈會系統和軟件是主角,但硬件是沒有被明示但卻至關重要的一環。APPSO 瞭解到,這次 Apple 智能在端側運行的是規模在 30 億參數的模型。
蘋果對此低調但卻充滿信心,據悉蘋果工程師認為這是目前最好的端側模型。
作為對比,不久前微軟發佈的端側小模型 Phi-Silica 參數為 33 億,而國內手機廠商在端側大部分場景的模型大約在 70 億-130 億參數之間。
參數越高大概率意味着更高的性能,但如果能以更小的參數規模實現同樣的性能,這對移動設備和大模型的結合有更大的意義。
而且業內很多研究已經證明,經過微調的小模型性能在某些使用場景下未必不如大模型。蘋果此前曝光的開源小模型 OpenELM ,就涵蓋 2.7 億、4.5 億、11 億和 30 億參數。
儘管蘋果認為用户看重的是體驗,並非參數規模,但端側模型大概率是蘋果在悄悄發力的地方。
如果順利,蘋果極有可能推動一波新的硬件浪潮,從 Vision Pro 到帶攝像頭的 AirPods,以及傳言中的家務機器人等。憑藉強大的設計生產和供應鏈能力,蘋果可以重新用軟件來塑造硬件。
這場沒有發佈任何新硬件的發佈會,可能才是近年來對蘋果硬件影響最大的一次發佈會。
Siri 將成為蘋果真正的操作系統
當蘋果要將 AI 的能力集成到操作系統中,Siri 就成為重要的橋樑。
在今天的媒體分享會上,蘋果公司機器學習和人工智能戰略高級副總裁 John Giannandrea 就表示:
我們之前在 WWDC 前瞻文章也預測過,蘋果 AI 最終的目標是實現這樣的場景:早上起牀,用一句「Siri」喚醒 Siri,再讓它打開微信公眾號「愛範兒」,朗讀最新的文章,就這樣在完全不用動手的情況下,聽取愛範兒的早報。
Siri 能變聰明,其實就是語義理解能力的提升,能像人一樣理解所有這些數據的含義。隨着時間的推移,這種理解會變得更加豐富。
大模型興起後的自然交互語言,一直被認為將取代我們現在和設備的圖形界面 GUI,背後是計算機對自然語言的理解能力大幅提升。
基於自然語言的交互到來,影響的不只是我們的隨身設備,應用的形態也將完全改變,比如 Siri 通過 API 調用具體的能力執行各種任務,甚至 app 都將不需要了,或以一種新的形態出現。
OpenAI 已經離職的聯合創始人 Andrej Karpathy 也表達了類似的觀點,他認為這是 Apple 最令人興奮的地方,並列舉了六點理由:
今天蘋果 WWDC 各種細節,都在隱隱指向這個未來。但蘋果也知道這大概率還不會在幾年內實現,所以只告訴你,起碼 Siri 好用多了。
過去兩年,我們最不缺的,其實就是 AIGC 帶的「Amazing」。但猶如手機和互聯網那般,深度嵌入生活肌理的技術或產品,還不見端倪。
潤物細無聲,才是技術革新的終極目標,也是 AI 的理想形態,這也是 Apple 智能最值得期待的地方。
資料來源:愛範兒(ifanr)
可當你上個月看過 OpenAI 和 Google 、微軟的發佈會,又會覺得這不像一場 AI 發佈會。

蘋果甚至沒有正式發佈一款大模型,沒有對比友商參數量、多模態能力這些常規環節,沒談 AGI 的未來,也沒有祭出像 Copilot 這種被媒體高呼「顛覆一切」的爆款應用。
蘋果反而造了一個叫 Apple Intelligence(下稱「Apple 智能」)的詞,這個諧音梗是在告訴人們,蘋果發佈的不是一款軟件或硬件,而是一種新的用户體驗。
庫克認為 AI 必須以用户為中心,需要無縫集成到你日常使用的體驗中:
引用它必須瞭解你,並基於你的個人背景,比如你的日常生活、你的人際關係、你的溝通等等,所有這一切都超出了人工智能的範圍。這是個人智能,也是蘋果公司的下一個重大舉措。蘋果選擇將 AI 能力滲透到整個生態之中,這意味着很難看到 GPT-4o 那種讓人歡呼的演示,但這種「沒有驚喜」和去年 iPhone 15 發佈時有所不同,那是智能手機宏大敍事終結的側寫。
而 Apple 智能,是在給 AI 應用鋪墊一種新的敍事,這可能不只是蘋果的新篇章。
個人智能和個人隱私
在 Apple 智能亮相時,蘋果就總結了它的五個特點:強大、易用、深度整合、個人化、私人化。
要想讓 AI 融合生活細節,甚至不被察覺,得讓 AI 甚至比你還了解你自己。這也意味着你的個人數據越多,就越可能實現,隨後不能不面對的問題就是:這是否要建立在讓渡個人隱私的基礎上實現?
這也是今天發佈會後,馬斯克批評蘋果的由來。
他甚至直接在庫克的推文下表示「要禁止所有蘋果設備進入我公司的辦公場所」,並對蘋果和 OpenAI 合作後用户隱私安全的保護提出質疑。
其實這也的確是用户會擔憂的問題,尤其對於活躍設備高達 22 億的蘋果。但這也和蘋果對隱私保護一向慎重的行事風格相悖。
過去蘋果設備和 AI 相關的功能基本都是依靠本地機器學習實現的,所需的數據量很少,很大程度上就是基於對個人隱私的考慮。
雖然蘋果在發佈會上對這些問題沒有一一介紹,但我們通過會後的一些媒體分享會,也瞭解到更多 Apple 智能在隱私方面的處理方式,可以試着釐清目前網絡上爭議較大的一些問題。

APPSO 獲悉,蘋果針對涉及雲端的數據處理提供了兩個新的解決方案。
首先,用户不必將所有數據、所有郵件、所有消息、所有照片、所有文檔發送到別人的雲端並存儲在那裏,以便服務器模型在需要時可以探測它們。
相反,用户的設備上的 Apple 智能會找出哪些小部分信息與回答這個問題相關。因此,向雲端提出的問題只包含這些小部分信息,而蘋果對小部分信息再進行保密處理。
蘋果創建了一個加密系統,比如 iPhone 只能與帶有指定標籤的服務器通信。換句話説,如果這台服務器上的軟件有任何更改,其簽名也會隨之改變,而你可以拒絕與其通信。
包括和 OpenAI 合作的用户數據處理也是,擁有註冊賬號的用户 IP 地址在使用服務時會被隱藏掉,OpenAI 也不被允許記錄用户請求。

這或許會在一定程度解答公眾的疑惑,蘋果也的確有必要在這方面披露更多信息。強調「個人化」的 Apple 智能,要實現發佈會上的藍圖,這是必須要處理好的問題。
而且蘋果和 OpenAI 的合作模式很可能並非獨家,未來在不同的場景,不同的地區,顯然是保留了其他大模型合作的空間。
這也並非蘋果一家廠商要面臨的問題,但無論是誰都必須慎重挑選合作伙伴,當 AI 隨着大量終端設備滲透生活,隱私和便利的交鋒會愈加激烈,即便被認為是忍受度更高的中國市場亦是如此。
一場沒有硬件的發佈會,卻對硬件影響很大
Apple 智能從命名到實現方式,都看出蘋果要以自己的方式來定義 AI 硬件,將 AI 能力滲透到整個生態之中,而不是推出某一個殺手級應用和功能。

這是和目前大量 AI 硬件最大的不同,去年開始硬件廠商掀起了 AI 硬件的潮流。當中不少都是將 AI 硬件簡單等同於大模型+終端設備,結果就是推出的往往是某個功能,更新實驗性質的半成品。
這也是 Ai Pin 和 Rabbit R1 等網紅 AI 硬件熱鬧一波就折戟沉沙的重要原因。

Apple 智能的思路和過去機器學習在蘋果產品的應用方式類似,儘管蘋果不怎麼提 AI ,但已經融入到很多常用的小功能,比如 AirPods Pro 自適應音頻模式也是通過機器學習實現。
很多人説在大模型時代蘋果已經掉隊,從單一技術上來説很可能的確如此,但蘋果需要的從來不是一個比 ChatGPT 更牛逼的模型,而是將算力轉化為整體而非局部的體驗。
雖然這場發佈會系統和軟件是主角,但硬件是沒有被明示但卻至關重要的一環。APPSO 瞭解到,這次 Apple 智能在端側運行的是規模在 30 億參數的模型。
蘋果對此低調但卻充滿信心,據悉蘋果工程師認為這是目前最好的端側模型。
作為對比,不久前微軟發佈的端側小模型 Phi-Silica 參數為 33 億,而國內手機廠商在端側大部分場景的模型大約在 70 億-130 億參數之間。

參數越高大概率意味着更高的性能,但如果能以更小的參數規模實現同樣的性能,這對移動設備和大模型的結合有更大的意義。
而且業內很多研究已經證明,經過微調的小模型性能在某些使用場景下未必不如大模型。蘋果此前曝光的開源小模型 OpenELM ,就涵蓋 2.7 億、4.5 億、11 億和 30 億參數。
儘管蘋果認為用户看重的是體驗,並非參數規模,但端側模型大概率是蘋果在悄悄發力的地方。
如果順利,蘋果極有可能推動一波新的硬件浪潮,從 Vision Pro 到帶攝像頭的 AirPods,以及傳言中的家務機器人等。憑藉強大的設計生產和供應鏈能力,蘋果可以重新用軟件來塑造硬件。
這場沒有發佈任何新硬件的發佈會,可能才是近年來對蘋果硬件影響最大的一次發佈會。
Siri 將成為蘋果真正的操作系統
當蘋果要將 AI 的能力集成到操作系統中,Siri 就成為重要的橋樑。
在今天的媒體分享會上,蘋果公司機器學習和人工智能戰略高級副總裁 John Giannandrea 就表示:
引用Siri 不再僅僅是一個語音助手,它實際上成為了一種設備系統。

我們之前在 WWDC 前瞻文章也預測過,蘋果 AI 最終的目標是實現這樣的場景:早上起牀,用一句「Siri」喚醒 Siri,再讓它打開微信公眾號「愛範兒」,朗讀最新的文章,就這樣在完全不用動手的情況下,聽取愛範兒的早報。
Siri 能變聰明,其實就是語義理解能力的提升,能像人一樣理解所有這些數據的含義。隨着時間的推移,這種理解會變得更加豐富。
大模型興起後的自然交互語言,一直被認為將取代我們現在和設備的圖形界面 GUI,背後是計算機對自然語言的理解能力大幅提升。
基於自然語言的交互到來,影響的不只是我們的隨身設備,應用的形態也將完全改變,比如 Siri 通過 API 調用具體的能力執行各種任務,甚至 app 都將不需要了,或以一種新的形態出現。
OpenAI 已經離職的聯合創始人 Andrej Karpathy 也表達了類似的觀點,他認為這是 Apple 最令人興奮的地方,並列舉了六點理由:
- 多模態 I/O:支持文本、音頻、圖像和視頻的讀寫功能。這些可以説是人類的原生 API。
- 代理性:允許操作系統和應用程序的所有部分通過「函數調用」進行互操作;內核進程的 LLM 可以根據用户查詢調度和協調工作。
- 無縫體驗:以高度無縫、快速、始終在線的方式完全集成這些功能。無需複製粘貼信息或提示工程,相應地調整 UI。
- 主動性:不僅是根據提示執行任務,而是預測提示、提供建議並主動執行。
- 委派層級:儘可能多地在設備上運行智能(Apple Silicon 非常適用),但也允許將工作委派到雲端。
- 模塊化:允許操作系統訪問和支持整個不斷增長的 LLM 生態系統(例如 ChatGPT 的發佈)。
- 隱私保護:<3
今天蘋果 WWDC 各種細節,都在隱隱指向這個未來。但蘋果也知道這大概率還不會在幾年內實現,所以只告訴你,起碼 Siri 好用多了。
過去兩年,我們最不缺的,其實就是 AIGC 帶的「Amazing」。但猶如手機和互聯網那般,深度嵌入生活肌理的技術或產品,還不見端倪。
潤物細無聲,才是技術革新的終極目標,也是 AI 的理想形態,這也是 Apple 智能最值得期待的地方。
資料來源:愛範兒(ifanr)