趕超 GPT-4o,最強大模型 Llama 3.1 405B 一夜封神,扎克伯格:開源引領新時代
就在剛剛,Meta 如期發佈了 Llama 3.1 模型。
簡單來説,最新發布的 Llama 3.1 405B 是 Meta 迄今為止最強大的模型,也是全球目前最強大的開源大模型,更是全球最強的大模型。
從今天起,不需要再爭論開源大模型與閉源大模型的孰優孰劣,因為 Llama 3.1 405B 用無可辯駁的實力證明路線之爭並不影響最終的技術實力。
先給大家總結一下 Llama 3.1 模型的特點:
附上模型下載地址:
https://huggingface.co/meta-llama
https://llama.meta.com/
超大杯登頂全球最強大模型,中杯大杯藏驚喜
本次發佈的 Llama 3.1 共有 8B、70B 和 405B 三個尺寸版本。
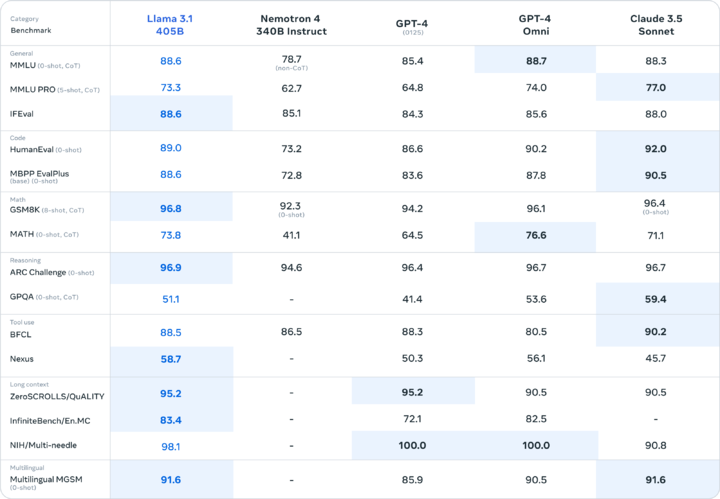
從基準測試結果來看,超大杯 Llama 3.1 405B 全方位耐壓了 GPT-3.5 Turbo、大部分基準測試得分超過了 GPT-4 0125。
而面對 OpenAI 此前發佈的最強閉源大模型 GPT-4o 和第一梯隊的 Claude 3.5 Sonnet,超大杯依然有着一戰之力,甚至可以僅從紙面參數上説,Llama 3.1 405B 標誌着開源大模型首次追上了閉源大模型。
具體細分到基準測試結果,Llama 3.1 405B 在 NIH/Multi-needle 基準測試的得分為 98.1,雖然比不上 GPT-4o,但也表明其在處理複雜信息的能力上堪稱完美。
並且 Llama 3.1 405B 在 ZeroSCROLLS/QUALITY 基準測試的得分為 95.2,也意味着其具有強大整合大量文本信息的能力,這些結果表明,LLaMA3.1 405B 模型在處理長文本方面出色,對於關注 LLM 在 RAG 方面性能的 AI 應用開發者來説,可謂是相當友好。
尤為關注的是,Human-Eval 主要是負責測試模型在理解和生成代碼、解決抽象邏輯能力的基準測試,而 Llama 3.1 405B 在與其他大模型的比拼中也是稍占上風。
除了主菜 Llama 3.1 405B,雖為配菜的 Llama 3.1 8B 和 Llama 3.1 70B 也上演了一出「以小勝大」的好戲。
就基準測試結果來看,Llama 3.1 8B 幾乎碾壓了 Gemma 2 9B 1T,以及 Mistral 7B Instruct,整體性能甚至比 Llama 3 8B 都有顯著提升。Llama 3.1 70B 更是能越級戰勝 GPT-3.5 Turbo 以及性能表現優異的 Mixtral 8×7B 模型。
據官方介紹,在這次發佈的版本中,Llama 研究團隊在 150 多個涵蓋多種語言的基準數據集上對模型性能進行了評估,以及團隊還進行了大量的人工評估。
最終得出的結論是:
Llama 3.1 405B 是如何煉成的
那 Llama 3.1 405B 是怎麼訓練的呢?
據官方博客介紹,作為 Meta 迄今為止最大的模型,Llama 3.1 405B 使用了超過 15 萬億個 token 進行訓練。
為了實現這種規模的訓練並在短時間內達到預期的效果,研究團隊也優化了整個訓練堆棧,在超過 16000 個 H100 GPU 上進行訓練,這也是第一個在如此大規模上訓練的 Llama 模型。
團隊也在訓練過程中做了一些優化,重點是保持模型開發過程的可擴展性和簡單性:
Meta 官方表示,在 Scaling Law 的影響之下,新的旗艦模型在性能上超過了使用相同方法訓練的小型模型。
研究團隊還利用了 405B 參數模型來提升小型模型的訓練後質量。
為了支持 405B 規模模型的大規模生產推理,研究團隊將模型從 16 位(BF16)精度量化到 8 位(FP8)精度,這樣做有效減少了所需的計算資源,並使得模型能夠在單個服務器節點內運行。
Llama 3.1 405B 還有一些值得發掘的細節,比如其在設計上注重實用性和安全性,使其能夠更好地理解和執行用户的指令。
通過監督微調、拒絕採樣和直接偏好優化等方法,在預訓練模型基礎上進行多輪對齊,構建聊天模型,Llama 3.1 405B 也能夠更精確地適應特定的使用場景和用户需求,提高實際應用的表現。
值得一提的是,Llama 研究團隊使用合成數據生成來產生絕大多數 SFT 示例,這意味着他們不是依賴真實世界的數據,而是通過算法生成的數據來訓練模型。
此外,研究團隊團隊通過多次迭代過程,不斷改進合成數據的質量。為了確保合成數據的高質量,研究團隊採用了多種數據處理技術進行數據過濾和優化。
通過這些技術,團隊能夠擴展微調數據量,使其不僅適用於單一功能,而是可以跨多個功能使用,增加了模型的適用性和靈活性。
簡單來説,這種合成數據的生成和處理技術的應用,其作用在於創建大量高質量的訓練數據,從而有助於提升模型的泛化能力和準確性。
作為開源模型路線的擁躉,Meta 也在 Llama 模型的「配套設施」上給足了誠意。
值得注意的是,新開源協議裏,Meta 不再禁止用 Llama 3 來改進其他模型了,這其中也包括最強的 Llama 3.1 405B,真·開源大善人。
附上 92 頁論文訓練報告地址:
https://ai.meta.com/research/publications/the-llama-3-herd-of-models/
一個由開源引領的新時代
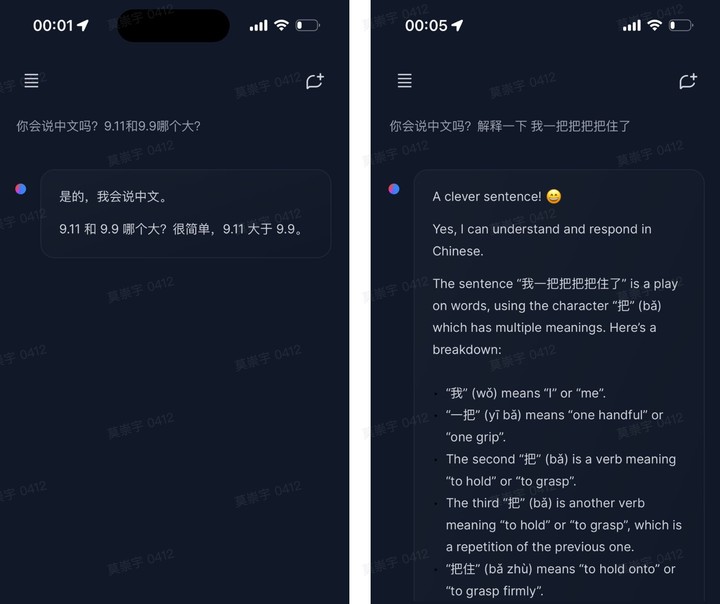
網友 @ZHOZHO672070 也火速在 Hugging Chat 上測試了一下 Llama 3.1 405B Instruct FP8 對兩個經典問題的回答情況。
遺憾的的是, Llama 3.1 405B 在解決「9.11 和 9.9 誰更大」的難題上遭遇翻車,不過再次嘗試之下,又給出了正確答案。而在「我一把把把住了」的拼音標註上,其表現也尚可。
網友更是隻用了不到 10 分鐘的時間,就使用 Llama 3.1 模型快速構建和部署了一個聊天機器人。
另外,Llama 內部科學家 @astonzhangAZ 也在 X 上透露,其研究團隊目前正在考慮將圖像、視頻和語音功能集成到 Llama 3 之中。
開源和閉源之爭,在大模型時代依然延續着,但今天 Meta Llama 3.1 新模型的發佈為這場辯論畫上了句號。
Meta 官方表示,「到目前為止,開源大型語言模型在功能和性能方面大多落後於封閉式模型。現在,我們正迎來一個由開源引領的新時代。」
Meta Llama 3.1 405B 的誕生證明了一件事情,模型的能力不在於開或閉,而是在於資源的投入、在於背後的人和團隊等等,Meta 選擇開源或許出於很多因素,但總會有人扛起這面大旗。
而作為第一個吃螃蟹的巨頭,Meta 也因此收穫了首個超越最強閉源大模型的 SOTA 稱號。
Meta CEO 扎克伯格在今天發佈的長文《Open Source AI Is the Path Forward》中寫道:
「從明年開始,我們預計未來的 Llama 將成為業內最先進的。但在此之前,Llama 已經在開源性、可修改性和成本效率方面領先。」
開源 AI 模型或許也志不在超越閉源,或出於技術平權,不會讓其成為少數人牟利的手段,或出於眾人拾柴火焰高,推動 AI 生態的繁榮發展。
正如扎克伯格在其長文末尾所描述的願景那樣:
資料來源:愛範兒(ifanr)
簡單來説,最新發布的 Llama 3.1 405B 是 Meta 迄今為止最強大的模型,也是全球目前最強大的開源大模型,更是全球最強的大模型。
從今天起,不需要再爭論開源大模型與閉源大模型的孰優孰劣,因為 Llama 3.1 405B 用無可辯駁的實力證明路線之爭並不影響最終的技術實力。
先給大家總結一下 Llama 3.1 模型的特點:
- 包含 8B、70B 和 405B 三個尺寸,最大上下文提升到了 128K,支持多語言,代碼生成性能優秀,具有複雜的推理能力和工具使用技巧
- 從基準測試結果來看,Llama 3.1 超過了 GPT-4 0125,與 GPT-4o、Claude 3.5 互有勝負
- 提供開放/免費的模型權重和代碼,許可證允許用户進行微調,將模型蒸餾到其他形式,並支持在任何地方部署
- 提供 Llama Stack API,便於集成使用,支持協調多個組件,包括調用外部工具
附上模型下載地址:
https://huggingface.co/meta-llama
https://llama.meta.com/

超大杯登頂全球最強大模型,中杯大杯藏驚喜
本次發佈的 Llama 3.1 共有 8B、70B 和 405B 三個尺寸版本。
從基準測試結果來看,超大杯 Llama 3.1 405B 全方位耐壓了 GPT-3.5 Turbo、大部分基準測試得分超過了 GPT-4 0125。
而面對 OpenAI 此前發佈的最強閉源大模型 GPT-4o 和第一梯隊的 Claude 3.5 Sonnet,超大杯依然有着一戰之力,甚至可以僅從紙面參數上説,Llama 3.1 405B 標誌着開源大模型首次追上了閉源大模型。
具體細分到基準測試結果,Llama 3.1 405B 在 NIH/Multi-needle 基準測試的得分為 98.1,雖然比不上 GPT-4o,但也表明其在處理複雜信息的能力上堪稱完美。
並且 Llama 3.1 405B 在 ZeroSCROLLS/QUALITY 基準測試的得分為 95.2,也意味着其具有強大整合大量文本信息的能力,這些結果表明,LLaMA3.1 405B 模型在處理長文本方面出色,對於關注 LLM 在 RAG 方面性能的 AI 應用開發者來説,可謂是相當友好。

尤為關注的是,Human-Eval 主要是負責測試模型在理解和生成代碼、解決抽象邏輯能力的基準測試,而 Llama 3.1 405B 在與其他大模型的比拼中也是稍占上風。
除了主菜 Llama 3.1 405B,雖為配菜的 Llama 3.1 8B 和 Llama 3.1 70B 也上演了一出「以小勝大」的好戲。

就基準測試結果來看,Llama 3.1 8B 幾乎碾壓了 Gemma 2 9B 1T,以及 Mistral 7B Instruct,整體性能甚至比 Llama 3 8B 都有顯著提升。Llama 3.1 70B 更是能越級戰勝 GPT-3.5 Turbo 以及性能表現優異的 Mixtral 8×7B 模型。
據官方介紹,在這次發佈的版本中,Llama 研究團隊在 150 多個涵蓋多種語言的基準數據集上對模型性能進行了評估,以及團隊還進行了大量的人工評估。
最終得出的結論是:
引用我們的旗艦模型在多種任務上與頂尖的基礎模型,如 GPT-4、GPT-4o 和 Claude 3.5 Sonnet 等,具有競爭力。同時,我們的小型模型在與參數數量相近的封閉和開放模型相比時,也展現出了競爭力。
Llama 3.1 405B 是如何煉成的
那 Llama 3.1 405B 是怎麼訓練的呢?
據官方博客介紹,作為 Meta 迄今為止最大的模型,Llama 3.1 405B 使用了超過 15 萬億個 token 進行訓練。
為了實現這種規模的訓練並在短時間內達到預期的效果,研究團隊也優化了整個訓練堆棧,在超過 16000 個 H100 GPU 上進行訓練,這也是第一個在如此大規模上訓練的 Llama 模型。
團隊也在訓練過程中做了一些優化,重點是保持模型開發過程的可擴展性和簡單性:
- 選擇了僅進行少量調整的標準解碼器 Transformer 模型架構,而不是混合專家模型,以最大限度地提高訓練穩定性。
- 採用了一種迭代後訓練程序,每一輪都使用監督微調和直接偏好優化。這使得研究團隊能夠為每輪創建最高質量的合成數據,並提升每項功能的性能。
- 相較於舊版 Llama 模型,研究團隊改進了用於預訓練和後訓練的數據數量和質量,包括為預訓練數據開發更預處理和管理管道,為後訓練數據開發更嚴格的質量保證與過濾方法。
Meta 官方表示,在 Scaling Law 的影響之下,新的旗艦模型在性能上超過了使用相同方法訓練的小型模型。

研究團隊還利用了 405B 參數模型來提升小型模型的訓練後質量。
為了支持 405B 規模模型的大規模生產推理,研究團隊將模型從 16 位(BF16)精度量化到 8 位(FP8)精度,這樣做有效減少了所需的計算資源,並使得模型能夠在單個服務器節點內運行。
Llama 3.1 405B 還有一些值得發掘的細節,比如其在設計上注重實用性和安全性,使其能夠更好地理解和執行用户的指令。
通過監督微調、拒絕採樣和直接偏好優化等方法,在預訓練模型基礎上進行多輪對齊,構建聊天模型,Llama 3.1 405B 也能夠更精確地適應特定的使用場景和用户需求,提高實際應用的表現。
值得一提的是,Llama 研究團隊使用合成數據生成來產生絕大多數 SFT 示例,這意味着他們不是依賴真實世界的數據,而是通過算法生成的數據來訓練模型。
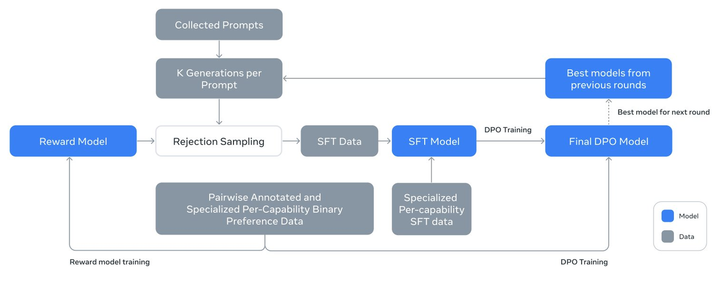
此外,研究團隊團隊通過多次迭代過程,不斷改進合成數據的質量。為了確保合成數據的高質量,研究團隊採用了多種數據處理技術進行數據過濾和優化。
通過這些技術,團隊能夠擴展微調數據量,使其不僅適用於單一功能,而是可以跨多個功能使用,增加了模型的適用性和靈活性。
簡單來説,這種合成數據的生成和處理技術的應用,其作用在於創建大量高質量的訓練數據,從而有助於提升模型的泛化能力和準確性。
作為開源模型路線的擁躉,Meta 也在 Llama 模型的「配套設施」上給足了誠意。
- Llama 模型作為 AI 系統的一部分,支持協調多個組件,包括調用外部工具。
- 發佈參考系統和開源示例應用程序,鼓勵社區參與和合作,定義組件接口。
- 通過「Llama Stack」標準化接口,促進工具鏈組件和智能體應用程序的互操作性。
- 模型發佈後,所有高級功能對開發者開放,包括合成數據生成等高級工作流。
- Llama 3.1 405B 內置工具大禮包,包含關鍵項目,簡化從開發到部署的流程。
值得注意的是,新開源協議裏,Meta 不再禁止用 Llama 3 來改進其他模型了,這其中也包括最強的 Llama 3.1 405B,真·開源大善人。
附上 92 頁論文訓練報告地址:
https://ai.meta.com/research/publications/the-llama-3-herd-of-models/
一個由開源引領的新時代
網友 @ZHOZHO672070 也火速在 Hugging Chat 上測試了一下 Llama 3.1 405B Instruct FP8 對兩個經典問題的回答情況。
遺憾的的是, Llama 3.1 405B 在解決「9.11 和 9.9 誰更大」的難題上遭遇翻車,不過再次嘗試之下,又給出了正確答案。而在「我一把把把住了」的拼音標註上,其表現也尚可。
網友更是隻用了不到 10 分鐘的時間,就使用 Llama 3.1 模型快速構建和部署了一個聊天機器人。
另外,Llama 內部科學家 @astonzhangAZ 也在 X 上透露,其研究團隊目前正在考慮將圖像、視頻和語音功能集成到 Llama 3 之中。
開源和閉源之爭,在大模型時代依然延續着,但今天 Meta Llama 3.1 新模型的發佈為這場辯論畫上了句號。
Meta 官方表示,「到目前為止,開源大型語言模型在功能和性能方面大多落後於封閉式模型。現在,我們正迎來一個由開源引領的新時代。」
Meta Llama 3.1 405B 的誕生證明了一件事情,模型的能力不在於開或閉,而是在於資源的投入、在於背後的人和團隊等等,Meta 選擇開源或許出於很多因素,但總會有人扛起這面大旗。
而作為第一個吃螃蟹的巨頭,Meta 也因此收穫了首個超越最強閉源大模型的 SOTA 稱號。

Meta CEO 扎克伯格在今天發佈的長文《Open Source AI Is the Path Forward》中寫道:
「從明年開始,我們預計未來的 Llama 將成為業內最先進的。但在此之前,Llama 已經在開源性、可修改性和成本效率方面領先。」
開源 AI 模型或許也志不在超越閉源,或出於技術平權,不會讓其成為少數人牟利的手段,或出於眾人拾柴火焰高,推動 AI 生態的繁榮發展。
正如扎克伯格在其長文末尾所描述的願景那樣:
引用我相信 Llama 3.1 版本將成為行業的一個轉折點,大多數開發人員將開始轉向主要使用開源技術,我期待這一趨勢從現在開始持續發展……共同致力於將 AI 的福祉帶給全球的每一個人。
資料來源:愛範兒(ifanr)