魔幻黑科技!華人學者推出視頻修復 AI,可換天造物,秒變科幻大片
AI修圖到底有多強?
前幾日,Adobe Max 大會剛剛結束,Photoshop 2021版便登上了國外各大媒體版面。
其原因是,新版Ps工具中內置了AI驅動工具,諸如“天空置換”等高難度修圖問題,現在點點鼠標就可以輕鬆實現,而且效果遠超手動操作。
無論是拍人拍景或是其他,“天空”都可以説是攝像中的關鍵元素。比如,一張平平無奇的景色圖加上落日餘暉的天空色調,是不是有內味了?
對於短視頻愛好者來説,如果也能達到如此處理效果豈不是更佳?
沒錯,今天小編就是要給大家介紹一款基於原生視頻的AI處理方法,不僅可以一鍵切置換天空背景,還可以打造任意“天空之城”。
AI視頻修復新玩法
這項AI處理方法來自密歇根大學的一位華人博士後的最新研究。該方法基於視覺技術可一鍵調整視頻中的天空背景和天氣轉換。
比如,《星際迷航》等科幻電影中經常出現的浩瀚星空、宇宙飛船,也可以利用這項技術融入隨手拍的視頻中。
公路片秒變科幻片,畫面毫無違和感。
視頻中的藍色的天空背景也隨飛船變成了灰濛濛的色調,一種世界末日的即視感有木有?
當然它的玩法還不止如此。
動漫迷也可以創建自己的移動城堡。喜歡《天空之城》《哈爾的移動城堡》的朋友應該對這一幕應該非常熟悉。
又或者在視頻中掛一個超級月亮,又是另一番景象。
好像只要腦洞夠大,利用這項AI技術,視頻創作就有無限種玩法。
另外,它還具備天氣轉換的功能,比如晴空萬里、陰雨綿綿、雷雨交加等各種天氣都可以在視頻中隨意切換。
喜歡玩Vlog的朋友聽着是不是非常心動了?研究人員表示,現在已經在考慮將其製作成插件/腳本的形式,方便相關從業者或行業使用。
在此之前,這項技術的AI代碼已經在Github開源,懂技術的朋友可以優先安裝體驗了~
Github地址:https://github.com/jiupinjia/SkyAR
技術原理
不同於傳統研究,研究人員提出了一種完全基於視覺的解決方案。它的好處就是可以處理非靜態圖像,同時不受拍攝設備的限制,也不需要用户交互,可以處理在線或離線視頻。
上述實驗視頻,均是通過手持智能手機和行車記錄儀在野外拍攝的。經過該方法處理後,其在視頻質量、運動動態、照明轉換方面都達到了較高的保真度。比如在浮動城堡,超級月亮樣例中,使用單個NVIDIA Titan XP GPU卡,該方法可以在輸出分辨率為640 x 320時達到24 fps的實時處理速度,在854 x 480時達到接近15 fps的實時處理速度。
具體來説,該方法分為三個核心模塊:
完整框架如下圖:
天空遮罩框架:利用深卷積神經網絡(CNN)的優勢,在一個像素級迴歸框架下對天空冰雹進行預測,該框架可以產生粗尺度和細尺度的天空濛版。天空遮罩框架由一個分段編碼器( Segmentation Encoder )、一個掩模預測解碼器(Mask Prediction Decoder)和一個軟細化模塊(Soft Refinement Module)組成。其中,編碼器的目的是學習下采樣輸入圖像的中間特徵表示。解碼器被用來訓練和預測粗糙的天空。優化模塊同時接收粗糙的天空濛版和高分辨率輸入,並生成一個高精度的天空濛版。
運動估計:研究人員直接估計了目標在無窮遠處的運動,並創建了一個用於圖像混合的天空盒(Skybox),通過將360°天空盒模板圖像混合到透視窗口來渲染虛擬天空背景。
假設天空模式的運動是由一個矩陣M
R
來模擬的。 由於天空中的物體(如雲、太陽或月亮)應該位於同一個位置,假設它們的透視變換參數是固定值,並且已經包含在天空盒背景圖像中,然後使用迭代Lucas-Kanade和金字塔方法計算光學流,從而可以逐幀跟蹤一組稀疏特徵點。對於每對相鄰幀,給定兩組2D特徵點,使用基於RANSAC的魯棒模糊估計來計算具有四個自由度(僅限於平移、旋轉和均勻縮放)的最佳2D變換。
圖像融合:在預測天空濛版時,輸出像素值越高,表示像素屬於天空背景的概率越高。在常規方法中,通常利用圖像遮罩方程,將新合成的視頻幀與背景進行線性組合,以作為它們的像素級組合權重。
但由於前景色和背景色可能具有不同的色調和強度,因此直接進行上述方法可能會導致不切實際的結果。 因此,研究人員應用重新着色和重新照明技術將顏色和強度從背景轉移到前景。
實驗結果
研究人員採用了天空電視台上的一個數據集。 該數據集基於AED20K數據集構建而成,包括多個子集,其中每個子集對應於使用不同方法創建真實的填空遮罩。
本次試驗使用“ADE20K+DE+GF”子集進行了培訓和評估,該訓練集中有9187張圖像,驗證集中有885張圖像。以下為基於該方法的視頻天空增強效果:
最左邊是輸入視頻的起始幀,右邊的圖像序列是不同時間段下的輸出效果
天氣轉換的效果,分別為晴到多雲,晴到小雨,多雲到晴天以及多雲到多雨。
需要強調的是,在合成雨天圖像時,研究人員通過屏幕混合在結果的頂部添加動態雨層(視頻源)和霧層。 結果顯示,只需對skybox模板和重新照明因子稍作修改,就可以實現視覺逼真的天氣轉換。
與CycleGAN的比較結果。CycleGAN是一種基於條件生成對抗網絡的非成對圖像到圖像轉換方法。在定性方面,該方法表現出更高的保真度。
第一行為兩個原始的輸入幀;第三行為CycleGAN結果
在定性比較上,PI和NIQE的得分值越低越好。
可以看出,該方法在定量指標和視覺質量方面都優於CycleGAN。
更多論文詳細內容,可參見:https://arxiv.org/abs/2010.11800
相關作者
Zhengxia Zou,是該項研究的第一作者,目前是密歇根大學安娜堡分校的博士後研究員 。
他於2013年和2018年獲得北京航空航天大學的學士學位和博士學位,後加入密歇根大學,其研究興趣包括計算機視覺在遙感、自動駕駛以及視頻遊戲中的相關應用。
近幾年,其發表的多篇相關論文被ACM、CVPR以及AAAI頂會收錄。
對於該項研究,Zhengxia Zou認為,除了視頻領域的應用外,還有一個潛在應用空間—數據擴充。 他説,
不過,目前研究也存在一定的侷限性,主要體現在兩個方面,
其原因是用於運動估計的特徵點被假定為位於同一位置,並且使用距離第二遠的特徵點來估計運動會不可避免地引入誤差。
因此,在未來的工作中,研究會着重於三個方向進行優化:第一是自適應天空光照;第二是魯棒背景運動估計;第三是探索基於天空渲染的數據增強對目標檢測和分割的有效性。
引用鏈接:
https://jiupinjia.github.io/skyar/
https://www.reddit.com/r/MachineLearning/comments/jh9wej/r_this_ai_finally_lets_you_fake_dramatic_sky/
雷鋒網雷鋒網雷鋒網(公眾號:雷鋒網)
雷鋒網原創文章,未經授權禁止轉載。詳情見轉載須知。
資料來源:雷鋒網
作者/編輯:貝爽
前幾日,Adobe Max 大會剛剛結束,Photoshop 2021版便登上了國外各大媒體版面。
其原因是,新版Ps工具中內置了AI驅動工具,諸如“天空置換”等高難度修圖問題,現在點點鼠標就可以輕鬆實現,而且效果遠超手動操作。
無論是拍人拍景或是其他,“天空”都可以説是攝像中的關鍵元素。比如,一張平平無奇的景色圖加上落日餘暉的天空色調,是不是有內味了?

對於短視頻愛好者來説,如果也能達到如此處理效果豈不是更佳?
沒錯,今天小編就是要給大家介紹一款基於原生視頻的AI處理方法,不僅可以一鍵切置換天空背景,還可以打造任意“天空之城”。
AI視頻修復新玩法
這項AI處理方法來自密歇根大學的一位華人博士後的最新研究。該方法基於視覺技術可一鍵調整視頻中的天空背景和天氣轉換。
比如,《星際迷航》等科幻電影中經常出現的浩瀚星空、宇宙飛船,也可以利用這項技術融入隨手拍的視頻中。

公路片秒變科幻片,畫面毫無違和感。
視頻中的藍色的天空背景也隨飛船變成了灰濛濛的色調,一種世界末日的即視感有木有?

當然它的玩法還不止如此。
動漫迷也可以創建自己的移動城堡。喜歡《天空之城》《哈爾的移動城堡》的朋友應該對這一幕應該非常熟悉。

又或者在視頻中掛一個超級月亮,又是另一番景象。

好像只要腦洞夠大,利用這項AI技術,視頻創作就有無限種玩法。
另外,它還具備天氣轉換的功能,比如晴空萬里、陰雨綿綿、雷雨交加等各種天氣都可以在視頻中隨意切換。


喜歡玩Vlog的朋友聽着是不是非常心動了?研究人員表示,現在已經在考慮將其製作成插件/腳本的形式,方便相關從業者或行業使用。
在此之前,這項技術的AI代碼已經在Github開源,懂技術的朋友可以優先安裝體驗了~

Github地址:https://github.com/jiupinjia/SkyAR
技術原理
不同於傳統研究,研究人員提出了一種完全基於視覺的解決方案。它的好處就是可以處理非靜態圖像,同時不受拍攝設備的限制,也不需要用户交互,可以處理在線或離線視頻。
上述實驗視頻,均是通過手持智能手機和行車記錄儀在野外拍攝的。經過該方法處理後,其在視頻質量、運動動態、照明轉換方面都達到了較高的保真度。比如在浮動城堡,超級月亮樣例中,使用單個NVIDIA Titan XP GPU卡,該方法可以在輸出分辨率為640 x 320時達到24 fps的實時處理速度,在854 x 480時達到接近15 fps的實時處理速度。
具體來説,該方法分為三個核心模塊:
- 天空遮罩框架(Sky Matting Network):用於檢測視頻幀中天空區域的視頻框架。該框架是採用了基於深度學習的預測管道,能夠產生更精確的檢測結果和更具視覺效果的天空濛版。
- 運動估計(Motion Estimation):用於恢復天空運動的運動估計器。天空視頻需要在真實攝像機的運動下進行渲染和同步。
- 圖像融合(Image Blending):用於將用户指定的天空模板混合到視頻幀中的Skybox。除此之外,還用於重置和着色,使混合結果在其顏色和動態範圍內更具視覺逼真感。
完整框架如下圖:

天空遮罩框架:利用深卷積神經網絡(CNN)的優勢,在一個像素級迴歸框架下對天空冰雹進行預測,該框架可以產生粗尺度和細尺度的天空濛版。天空遮罩框架由一個分段編碼器( Segmentation Encoder )、一個掩模預測解碼器(Mask Prediction Decoder)和一個軟細化模塊(Soft Refinement Module)組成。其中,編碼器的目的是學習下采樣輸入圖像的中間特徵表示。解碼器被用來訓練和預測粗糙的天空。優化模塊同時接收粗糙的天空濛版和高分辨率輸入,並生成一個高精度的天空濛版。
運動估計:研究人員直接估計了目標在無窮遠處的運動,並創建了一個用於圖像混合的天空盒(Skybox),通過將360°天空盒模板圖像混合到透視窗口來渲染虛擬天空背景。
假設天空模式的運動是由一個矩陣M
引用2
R
引用33
來模擬的。 由於天空中的物體(如雲、太陽或月亮)應該位於同一個位置,假設它們的透視變換參數是固定值,並且已經包含在天空盒背景圖像中,然後使用迭代Lucas-Kanade和金字塔方法計算光學流,從而可以逐幀跟蹤一組稀疏特徵點。對於每對相鄰幀,給定兩組2D特徵點,使用基於RANSAC的魯棒模糊估計來計算具有四個自由度(僅限於平移、旋轉和均勻縮放)的最佳2D變換。
圖像融合:在預測天空濛版時,輸出像素值越高,表示像素屬於天空背景的概率越高。在常規方法中,通常利用圖像遮罩方程,將新合成的視頻幀與背景進行線性組合,以作為它們的像素級組合權重。
但由於前景色和背景色可能具有不同的色調和強度,因此直接進行上述方法可能會導致不切實際的結果。 因此,研究人員應用重新着色和重新照明技術將顏色和強度從背景轉移到前景。
實驗結果
研究人員採用了天空電視台上的一個數據集。 該數據集基於AED20K數據集構建而成,包括多個子集,其中每個子集對應於使用不同方法創建真實的填空遮罩。
本次試驗使用“ADE20K+DE+GF”子集進行了培訓和評估,該訓練集中有9187張圖像,驗證集中有885張圖像。以下為基於該方法的視頻天空增強效果:

最左邊是輸入視頻的起始幀,右邊的圖像序列是不同時間段下的輸出效果
天氣轉換的效果,分別為晴到多雲,晴到小雨,多雲到晴天以及多雲到多雨。

需要強調的是,在合成雨天圖像時,研究人員通過屏幕混合在結果的頂部添加動態雨層(視頻源)和霧層。 結果顯示,只需對skybox模板和重新照明因子稍作修改,就可以實現視覺逼真的天氣轉換。
與CycleGAN的比較結果。CycleGAN是一種基於條件生成對抗網絡的非成對圖像到圖像轉換方法。在定性方面,該方法表現出更高的保真度。

第一行為兩個原始的輸入幀;第三行為CycleGAN結果
在定性比較上,PI和NIQE的得分值越低越好。
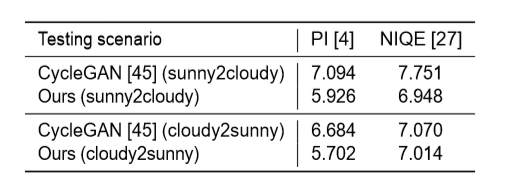
可以看出,該方法在定量指標和視覺質量方面都優於CycleGAN。
更多論文詳細內容,可參見:https://arxiv.org/abs/2010.11800
相關作者
Zhengxia Zou,是該項研究的第一作者,目前是密歇根大學安娜堡分校的博士後研究員 。
他於2013年和2018年獲得北京航空航天大學的學士學位和博士學位,後加入密歇根大學,其研究興趣包括計算機視覺在遙感、自動駕駛以及視頻遊戲中的相關應用。
近幾年,其發表的多篇相關論文被ACM、CVPR以及AAAI頂會收錄。
對於該項研究,Zhengxia Zou認為,除了視頻領域的應用外,還有一個潛在應用空間—數據擴充。 他説,
引用數據集的規模和質量是計算機視覺技術的基礎,在現實場景中,即使ImageNet、MS-COCO等大規模數據集,在應用中也存在採樣偏差帶來的侷限,而該方法對於提高深度學習模型在檢測、分割、跟蹤等各種視覺任務中的泛化能力具有很大的潛力。
不過,目前研究也存在一定的侷限性,主要體現在兩個方面,
- 一是天空遮罩網絡無法檢測到夜間視頻中的天空區域。
- 二是當視頻中某段時間內沒有天空像素,或者沒有紋理時,天空背景的運動就無法精確建模。
其原因是用於運動估計的特徵點被假定為位於同一位置,並且使用距離第二遠的特徵點來估計運動會不可避免地引入誤差。
因此,在未來的工作中,研究會着重於三個方向進行優化:第一是自適應天空光照;第二是魯棒背景運動估計;第三是探索基於天空渲染的數據增強對目標檢測和分割的有效性。
引用鏈接:
https://jiupinjia.github.io/skyar/
https://www.reddit.com/r/MachineLearning/comments/jh9wej/r_this_ai_finally_lets_you_fake_dramatic_sky/
雷鋒網雷鋒網雷鋒網(公眾號:雷鋒網)
雷鋒網原創文章,未經授權禁止轉載。詳情見轉載須知。

資料來源:雷鋒網
作者/編輯:貝爽