英偉達 H100 首次亮相 MLPerf,測試結果刷新紀錄
雷峯網(公眾號:雷峯網)消息,北京時間9月9日,MLCommons社區發佈了最新的MLPerf 2.1基準測試結果,新一輪基準測試擁有近5300個性能結果和2400個功耗測量結果,分別比上一輪提升了1.37倍和1.09倍,MLPerf的適用範圍進一步擴大。
阿里巴巴、華碩、Azure、壁仞科技、戴爾、富士通、技嘉、H3C、HPE、浪潮、英特爾、Krai、聯想、Moffett、Nettrix、Neural Magic、英偉達、OctoML、高通、SAPEON 和 Supermicro 均是本輪測試的貢獻者。
其中,英偉達表現依然亮眼,首次攜H100參加MLPerf測試,並在所有工作負載中刷新世界紀錄。
H100打破世界記錄,較A100性能提升4.5倍
英偉達於今年3月份發佈基於新架構NVIDIA Hopper的H100 GPU,與兩年前推出的NVIDIA Ampere架構相比,實現了數量級的性能飛躍。黃仁勳曾在 GTC 2022 上表示,20個H100 GPU便可以承託相當於全球互聯網的流量,能夠幫助客户推出先進的推薦系統及實時運行數據推理的大型語言模型。
令一眾AI從業者期待的H100原本定於2022年第三季度正式發貨,目前處於接受預定狀態,用户的真實使用情況和H100的實際性能尚不可知,因此可以通過最新一輪的MLPerf測試得分提前感受H100的性能。
在本輪測試中,對比Intel Sapphire Rapids、Qualcomm Cloud AI 100、Biren BR104、SAPEON X220-enterprise,NVIDIA H100不僅提交了數據中心所有六個神經網絡模型的測試成績,且在單個服務器和離線場景中均展現出吞吐量和速度方面的領先優勢。
以NVIDIA A100相比,H100在MLPerf模型規模最大且對性能要求最高的模型之一——用於自然語言處理的BERT模型中表現出4.5倍的性能提升,在其他五個模型中也都有1至3倍的性能提升。H100之所以能夠在BERT模型上表現初出色,主要歸功於其Transformer Engine。
其他同樣提交了成績的產品中,只有Biren BR104在離線場景中的ResNet50和BERT-Large模型下,相比NVIDIA A100有一倍多的性能提升,其他提交成績的產品均未在性能上超越A100。
而在數據中心和邊緣計算類別的場景中,A100 GPU的測試成績依然不俗,得益於NVIDIA AI軟件的不斷改進,與2020年7月首次亮相MLPerf相比,A100 GPU實現了6倍的性能提升。
追求AI通用性,測試成績覆蓋所有AI模型
由於用户在實際應用中通常需要採用許多不同類型的神經網絡協同工作,例如一個AI應用可能需要理解用户的語音請求、對圖像進行分類、提出建議,然後以語音迴應,每個步驟都需要用到不同的AI模型。
正因如此,MLPerf基準測試涵蓋了包括計算機視覺、自然語言處理、推薦系統、語音識別等流行的AI工作負載和場景,以便於確保用户獲得可靠且部署靈活的性能。這也意味着,提交的測試成績覆蓋的模型越多,成績越好,其AI能力更加具備通用性。
在此輪測試中,英偉達AI依然是唯一能夠在數據中心和邊緣計算中運行所有MLPerf推理工作負載和場景的平台。
在數據中心方面,A100和H100都提交了六個模型測試成績。
在邊緣計算方面,NVIDIA Orin運行了所有MLPerf基準測試,且是所有低功耗系統級芯片中贏得測試最多的芯片。
Orin是將NVIDIA Ampere架構GPU和Arm CPU內核集成到一塊芯片中,主要用於機器人、自主機器、醫療機械和其他形式的邊緣嵌入式計算。
目前,Orin已經被用在NVIDIA Jetson AGX Orin開發者套件以及機器人和自主系統生成模考,並支持完整的NVIDIA AI軟件堆棧,包括自動駕駛汽車平台、醫療設備平台和機器人平台。
與4月在MLPerf上的首次亮相相比,Orin能效提高了50%,其運行速度和平均能效分別比上一代Jetson AGX Xavier 模塊高出5倍和2倍。
追求通用型的NVIDIA AI 正在被業界廣泛的機器學習生態系統支持。在這一輪基準測試中,有超過70 項提交結果在 NVIDIA 平台上運行。例如,Microsoft Azure 提交了在其雲服務上運行NVIDIA AI 的結果。
雷峯網
相關文章:
MLPerf最新結果公佈,英偉達仍是「王者」
MLPerf最新榜單公佈,寧暢狂攬59項第一
IPU首度公開MLPerf成績,性價比收益勝過英偉達
雷峯網原創文章,未經授權禁止轉載。詳情見轉載須知。
資料來源:雷鋒網
作者/編輯:吳優
阿里巴巴、華碩、Azure、壁仞科技、戴爾、富士通、技嘉、H3C、HPE、浪潮、英特爾、Krai、聯想、Moffett、Nettrix、Neural Magic、英偉達、OctoML、高通、SAPEON 和 Supermicro 均是本輪測試的貢獻者。
其中,英偉達表現依然亮眼,首次攜H100參加MLPerf測試,並在所有工作負載中刷新世界紀錄。
H100打破世界記錄,較A100性能提升4.5倍
英偉達於今年3月份發佈基於新架構NVIDIA Hopper的H100 GPU,與兩年前推出的NVIDIA Ampere架構相比,實現了數量級的性能飛躍。黃仁勳曾在 GTC 2022 上表示,20個H100 GPU便可以承託相當於全球互聯網的流量,能夠幫助客户推出先進的推薦系統及實時運行數據推理的大型語言模型。
令一眾AI從業者期待的H100原本定於2022年第三季度正式發貨,目前處於接受預定狀態,用户的真實使用情況和H100的實際性能尚不可知,因此可以通過最新一輪的MLPerf測試得分提前感受H100的性能。
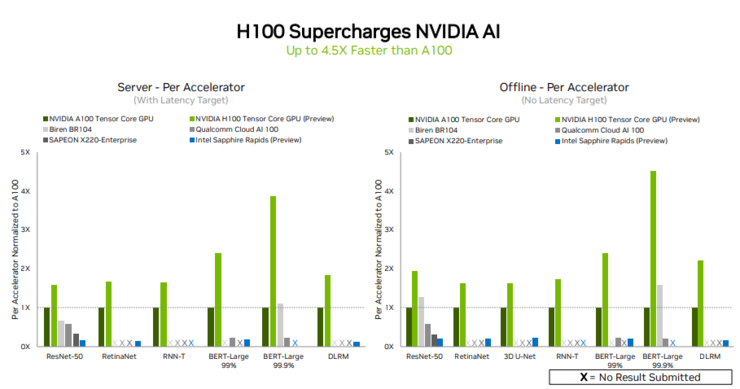
在本輪測試中,對比Intel Sapphire Rapids、Qualcomm Cloud AI 100、Biren BR104、SAPEON X220-enterprise,NVIDIA H100不僅提交了數據中心所有六個神經網絡模型的測試成績,且在單個服務器和離線場景中均展現出吞吐量和速度方面的領先優勢。
以NVIDIA A100相比,H100在MLPerf模型規模最大且對性能要求最高的模型之一——用於自然語言處理的BERT模型中表現出4.5倍的性能提升,在其他五個模型中也都有1至3倍的性能提升。H100之所以能夠在BERT模型上表現初出色,主要歸功於其Transformer Engine。
其他同樣提交了成績的產品中,只有Biren BR104在離線場景中的ResNet50和BERT-Large模型下,相比NVIDIA A100有一倍多的性能提升,其他提交成績的產品均未在性能上超越A100。
而在數據中心和邊緣計算類別的場景中,A100 GPU的測試成績依然不俗,得益於NVIDIA AI軟件的不斷改進,與2020年7月首次亮相MLPerf相比,A100 GPU實現了6倍的性能提升。
追求AI通用性,測試成績覆蓋所有AI模型
由於用户在實際應用中通常需要採用許多不同類型的神經網絡協同工作,例如一個AI應用可能需要理解用户的語音請求、對圖像進行分類、提出建議,然後以語音迴應,每個步驟都需要用到不同的AI模型。

正因如此,MLPerf基準測試涵蓋了包括計算機視覺、自然語言處理、推薦系統、語音識別等流行的AI工作負載和場景,以便於確保用户獲得可靠且部署靈活的性能。這也意味着,提交的測試成績覆蓋的模型越多,成績越好,其AI能力更加具備通用性。
在此輪測試中,英偉達AI依然是唯一能夠在數據中心和邊緣計算中運行所有MLPerf推理工作負載和場景的平台。
在數據中心方面,A100和H100都提交了六個模型測試成績。
在邊緣計算方面,NVIDIA Orin運行了所有MLPerf基準測試,且是所有低功耗系統級芯片中贏得測試最多的芯片。

Orin是將NVIDIA Ampere架構GPU和Arm CPU內核集成到一塊芯片中,主要用於機器人、自主機器、醫療機械和其他形式的邊緣嵌入式計算。
目前,Orin已經被用在NVIDIA Jetson AGX Orin開發者套件以及機器人和自主系統生成模考,並支持完整的NVIDIA AI軟件堆棧,包括自動駕駛汽車平台、醫療設備平台和機器人平台。
與4月在MLPerf上的首次亮相相比,Orin能效提高了50%,其運行速度和平均能效分別比上一代Jetson AGX Xavier 模塊高出5倍和2倍。
追求通用型的NVIDIA AI 正在被業界廣泛的機器學習生態系統支持。在這一輪基準測試中,有超過70 項提交結果在 NVIDIA 平台上運行。例如,Microsoft Azure 提交了在其雲服務上運行NVIDIA AI 的結果。
雷峯網
相關文章:
MLPerf最新結果公佈,英偉達仍是「王者」
MLPerf最新榜單公佈,寧暢狂攬59項第一
IPU首度公開MLPerf成績,性價比收益勝過英偉達
雷峯網原創文章,未經授權禁止轉載。詳情見轉載須知。
資料來源:雷鋒網
作者/編輯:吳優